

Авторы
Известно, что сегодня большое количество спама рассылается через сети зараженных компьютеров, управляемых удаленно хорошо организованными группами или отдельными лицами. Такие сети называются бот-сетями и являются объектами повышенного внимания для специалистов по IT-безопасности во всем мире.
В этой статье речь пойдет о методе автоматического выделения и блокирования таких сетей в режиме реального времени. Метод основан на статистическом подходе и использует тот факт, что компьютеры одной бот-сети так или иначе имеют некоторое сходство в поведении. Отслеживая почтовый трафик из большого количества разных источников в течение определенного промежутка времени, можно заметить, что некоторые потоки имеют схожие характеристики, что выделяет компьютеры — источники этого трафика из множества остальных машин, рассылающих почтовые сообщения. В зависимости от способа сравнения потоков, количества сообщений в каждом из них и числа локализованных источников можно сказать с большей или меньшей степенью вероятности, что эти источники составляют сеть зомби-компьютеров, т.е. бот-сеть.
Введение
Вместе с другими вредоносными действиями, такими как DDoS-атаки, хищение персональных данных, анализ трафика, распространение вредоносного ПО и др., рассылка спама является наиболее часто используемым применением бот-сетей. Существенные всплески спам-активности сегодня связывают с возрастающим использованием спамерами бот-сетей. Большие распределенные компьютерные сети трудно отслеживать, а динамичная природа IP-адресов машин, входящих в бот-сеть, делает практически невозможным использование традиционных списков запрещенных.
В этой статье представлен метод, который может быть использован для выделения и блокирования таких сетей практически в режиме реального времени. Метод является статистическим и предполагает, что мы можем наблюдать большое количество почтовых сообщений из различных источников. Чем больше источников анализируется и чем больше сообщений из каждого источника обрабатывается, тем точнее результаты.
Основная идея метода состоит в том, что распределение некоторых числовых параметров e-mail-сообщений, посланных из одного источника, сравнивается с такими же распределениями, полученными для других источников.
В самом простом случае все компьютеры бот-сети распространяют в точности одно и то же сообщение. Мы могли бы очень просто отследить такую сеть, собирая и сравнивая MD5-суммы сообщений из разных источников. Если найдутся сотни или тысячи компьютеров, рассылающих сообщения с одинаковой MD5-суммой, то это наверняка бот-сеть. Конечно, если нашей конечной целью является противодействие спаму, а не исследование бот-сетей, то в данном случае проще использовать другую технологию, называемую Distributed Checksum Clearinghouse (DCC), которая блокирует спам с помощью списков запрещенных MD5-сумм сообщений.
В реальности все гораздо сложнее. Содержание e-mail-сообщений меняется существенно даже внутри одной рассылки. Изменениям могут подвергаться текстовые части писем, размер и количество вложений, размеры картинок, кодировки, форматы и т.д. Как следствие, меняются многие параметры писем, делая трудным установление взаимосвязи между отдельными сообщениями. В этой ситуации для каждого IP-адреса мы можем построить распределение количества сообщений, посланных с него, по размеру сообщений. Построенные распределения затем сравниваются друг с другом. Конечно, для каждого хоста, рассылающего почту, такие распределения будут уникальны, но для компьютеров одной бот-сети они будут похожи. В этом вся суть. Сравниваются функции, а не скалярные величины! Интуитивно понятно, что если бы мы жили в мире, где нет бот-сетей, то было бы очень трудно среди наугад взятых нескольких миллионов хостов найти несколько тысяч, имеющих «очень похожие» «нетривиальные» законы распределения. Точные расчеты и многочисленные эксперименты подтверждают это предположение, и для некоторых выделенных сетей оценки величин ложных срабатываний (т.е. попадания «хороших» хостов в бот-сеть) были практически нулевые. Другие сети показали не столь очевидные результаты. Вообще, оценка вероятности ложных срабатываний для каждой выделенной бот-сети, рассматривается как часть метода и будет обсуждаться ниже.
Реализация
Поскольку речь идет о почтовых операциях в большом масштабе, система, спроектированная для борьбы со спамом, рассылаемым через бот-сети, должна быть значительно распределённой. Почтовые агенты (MTA) должны передавать информацию о почтовых сообщениях, которые они получают, на один или более серверов, где она будет накапливаться и анализироваться. Получившиеся в результате этого группы IP-адресов, классифицируемые как бот-сети, вместе с числовыми коэффициентами – весами, показывающими, насколько мы можем доверять этим группам, объединяются в списки запрещенных, которые могут быть доступны, например, через обычные DNS-запросы. Основная проблема здесь — динамическая природа IP-адресов, с которыми мы имеем дело. Большинство зараженных машин, входящих в бот-сеть, — это домашние компьютеры, подключенные к сетям своих провайдеров через dialup-, dsl-, cable- или LAN-соединения. IP-адреса для таких компьютеров часто выделяются динамически. Это означает, что обычное время жизни таких адресов измеряется часами, возможно днями. Система должна реагировать быстро, помещая адрес в список запрещенных, как только с него начинается рассылка спама, и удаляя его, как только он перестает попадать в бот-сеть.
Работа по выявлению бот-сетей, распространяющих спам, проводится в «Лаборатории Касперского» с октября 2006 года. На рис. 1 представлена схема движения потоков данных между элементами системы. Уже существовавшая в компании система, называемая Urgent Detection System (UDS), созданная в рамках другой технологии фильтрации спама, была адаптирована для наших целей и использована как средство доставки данных. Почтовые сообщения пересылаются из источников (S) к пунктам назначения (D) — системам, которые необходимо защищать от спама. В данной реализации метода единственным анализируемым атрибутом является размер сообщения. Размеры сообщений вместе с IP-адресами, с которых они были получены, передаются на один из UDS-серверов, где они накапливаются и далее передаются бот-анализатору. Для каждого полученного IP-адреса анализатор строит распределение количества сообщений по размерам и сравнивает их, создавая списки запрещенных IP-адресов, подлежащих блокированию. Данные распределений обновляются и обрабатываются каждые 2 часа для корректировки списков запрещенных, каждые 24 часа они заново инициализируются.
Несколько слов о том, как сравниваются распределения. Разработка эффективных алгоритмов, позволяющих быстро сравнивать распределения, — довольно сложная задача. Прямое сравнение «каждый с каждым» нескольких миллионов распределений потребовало бы многих часов вычислительной работы. В настоящей реализации метода каждое распределение делится на части, и именно эти части из различных распределений сравниваются после некоторого упорядочивания. Сам алгоритм — это итерационный процесс. Первая итерация приводит к наборам IP-адресов, являющимся грубым приближением к бот-сетям. Последующие итерации вырабатывают хорошо выделенные бот-сети. Требуется примерно 60-90 минут для обработки данных, накопленных за 24 часа.

Рис. 1
Ложные срабатывания
Независимо от того, с какой целью мы используем систему: для блокирования спама или просто для исследования бот-сетей, возникает вопрос, насколько мы можем доверять результатам. Нам необходимо оценить, сколько «хороших» хостов может быть ошибочно помещено в каждую получившуюся бот-сеть. Такие оценки сильно зависят от способа сравнения распределений. Строго говоря, необходимо определить метрическое пространство, в котором «живут» наши распределения. Метрика (т.е. расстояние между любыми двумя распределениями) должна выбираться тщательно, чтобы правильно отразить суть стоящих задач. На рис. 2 показано, как бы выглядело метрическое пространство в мире, где нет бот-сетей (точки на рисунке обозначают наши распределения или функционалы). Точки в рассматриваемой зоне расположены довольно равномерно, и невозможно покрыть много точек (распределений) шаром достаточно малого радиуса (шар радиуса R в метрическом пространстве — это набор точек, удаленных от центра на расстояние, меньшее R). В мире с бот-сетями (рис. 3) существуют области с высокой плотностью, которые можно покрыть шарами достаточно малого радиуса. Из рисунков понятно, что чем меньше радиус, тем меньше распределений (а значит и хостов) попадет в результирующую бот-сеть и тем меньше вероятность ложных срабатываний.
В данной реализации метода использовался практический подход оценки ложных срабатываний, где сохранялись 24-часовые распределения, которые не попали ни в одну из выделенных бот-сетей. Эти распределения представляют наш свободный от бот-сетей мир (рис. 2). Каждый раз, когда необходимо сделать оценку для бот-сети, мы восстанавливаем 24-часовые распределения за несколько (чем больше, тем лучше) суток, сохраненные месяц или два назад, берем одно распределение-представитель из бот-сети (то, что ближе к центру шара, упомянутого выше) и смотрим, как много распределений из нашего восстановленного, свободного от бот-сетей мира будут находится возле (т. е. внутри шара) распределения из бот-сети. Это число показывает, как много «хороших» хостов может оказаться в выделенной бот-сети. Для «хорошо определенной» бот-сети это число должно быть мало (0, 1, 2 или около того). Большие числа означают, что распределение (и вся сеть) слишком «тривиально», чтобы быть использовано в данном методе.
Более простой подход в оценке ложных срабатываний мог бы заключаться в определении «сложности» распределений бот-сети. Большое количество «сложных» распределений скорее всего составляют бот-сеть, приводящую к малому числу ложных срабатываний.
Важно также упомянуть так называемые «псевдоложные срабатывания». Наряду с контентом, предписанным владельцем бот-сети, компьютер может рассылать вполне легитимные сообщения. Если таких не спам-сообщений заметное число, то хост, скорее всего, не попадет в бот-сеть, так как «дополнительные» сообщения исказят его распределение. Однако это может быть не так, если эта легитимная почта не попала в сферу охвата нашей системы. Так что желательно предоставлять результирующие списки запрещенных только тем клиентам антиспам-системы, которые вносят вклад в распределения (т. е. посылают пары размер-адрес на UDS-серверы).

Рис. 2

Рис. 3
Некоторые результаты
В среднем каждые 24 часа выделяются несколько десятков бот-сетей. Количество адресов в каждой из них составляет от нескольких сотен до нескольких тысяч. В качестве примера ниже описаны две сети, выделенные в июле 2007 года. Одна из них имела до 2000 адресов, в основном из России, и наблюдалась в течение нескольких недель. Интересно отметить, что эта сеть была неактивна в выходные дни и, кроме того, только 20-25% IP-адресов обнаруживались на следующий день после того, как они были помещены в бот-сеть. В другой сети было около 200 адресов, зарегистрированных в Бразилии, Аргентине, Китае, Индии и других странах. Вообще, практически все сети за пределами России были представлены в урезанном виде из-за отсутствия достаточных статистических данных. На приведенных ниже диаграммах показаны распределения по странам для указанных бот-сетей.


Рис. 4-5
В конце статьи приведены 12 рисунков — типичные распределения, полученные для шести представителей первой и второй бот-сетей соответственно. В заголовке каждого рисунка приводится IP-адрес, доменное имя хоста, страна и количество сообщений, отправленных данным хостом за 24-часовой интервал. По оси абсцисс отложены размеры сообщений в байтах (100-байтовые интервалы), по оси ординат – количество сообщений. Например, точка с координатами X=5000 и Y=30 означает, что хост отправил 30 сообщений размером от 5000 до 5099 байт. Из рисунков видно, насколько похожи распределения одной сети, несмотря на различное количество сообщений, обработанных для получения таких распределений.
Заключение
Много деталей, касающихся особенностей реализации метода, упомянуто вскользь, еще больше их осталось за пределами этой статьи. Однако, зная основную идею метода, можно оценить его основные преимущества и недостатки. Главной проблемой, стоящей на пути реализации описанной технологии, является необходимость в большом объеме статистической информации, собранной из разных источников. Для уверенного анализа необходимо иметь информацию как минимум о нескольких десятках, а лучше сотен сообщений для каждого источника, что не всегда возможно. К тому же, пока статистика накапливается, спам-сообщения беспрепятственно доходят до пользователей. Другим недостатком является сложность алгоритмов анализа информации, которые также требуют тщательного тестирования и настройки для получения приемлемых результатов. К преимуществам относится простота реализации на стороне клиента и малый объем передаваемой информации. Метод является, по-видимому, одним из немногих позволяющих достаточно полно очертить границы зомби-сетей при их воздействии на определенные группы хостов. Так что помимо борьбы со спамом, он может использоваться в исследовательских целях. Дальнейшее развитие описанной технологии может быть связано с анализом распределений по другим, отличным от размера, параметрам, а также с анализом векторных распределений, построенных сразу по нескольким характеристикам сообщений.

Рис. 6

Рис. 7

Рис. 8
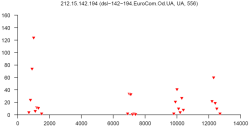
Рис. 9
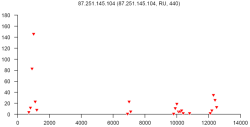
Рис. 10

Рис. 11
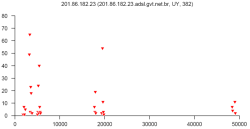
Рис. 12

Рис. 13

Рис. 14

Рис. 15

Рис. 16

Рис. 17
От тех же авторов




В той же категории












Метод согласованных распределений для выделения бот-сетей, рассылающих спам