

Авторы
Что такое инцидент ИБ и как на него реагировать?
 Руководство по реагированию на инциденты информационной безопасности (PDF)
Руководство по реагированию на инциденты информационной безопасности (PDF)
Несмотря на то, что за последние годы в ландшафте киберугроз не произошло никаких революционных изменений, растущая информатизация бизнес-процессов предоставляет злоумышленникам множество возможностей для атак. Они сосредотачивают внимание на целевых атаках и учатся использовать уязвимые места своих жертв более эффективно, стараясь при этом оставаться «ниже радаров». В результате возникает ощущаемый бизнесом эффект «NextGen-угроз» без появления новых типов вредоносного ПО.
К сожалению, корпоративные службы ИБ часто оказываются недостаточно подготовлены: их сотрудники недооценивают скорость, скрытность и эффективность современных кибератак, не отдают себе отчета в неэффективности старых подходов к обеспечению безопасности. Даже когда классические средства предотвращения, такие как антивирусные продукты, IDS/IPS и сканеры безопасности, дополняются детектирующими решениями, такими как SIEM и Anti-APT, весь этот дорогостоящий комплекс может использоваться не на полную мощность. А из-за непонимания того, что представляет собой инцидент, атаку, в конечном счете, не удается отразить.
Более подробную информацию об этапах организации кибератаки и реагирования на инциденты можно найти в полной версии данного руководства или получить в рамках обучающей программы «Лаборатории Касперского». Здесь же мы остановимся лишь на главном.
Планы наступления
Прежде всего стоит оговориться, что под целевыми атаками мы подразумеваем серьезные операции, подготовленные квалифицированными киберпреступниками. Хулиганские акции, вроде дефейса главной страницы сайта, совершаемые ради привлечения внимания или демонстрации возможностей, мы рассматривать не будем. Их успех, как правило, говорит об отсутствии в компании ИБ-службы как таковой, даже если штатное расписание говорит об обратном.
Базовые принципы, лежащие в основе любой целевой атаки – это тщательная подготовка и поэтапная стратегия. Именно последовательность этапов (известную как kill chain) мы и рассмотрим, взяв в качестве примера атаку на банк с целью хищения денег из банкоматов.
1. Разведка и сбор данных (Reconnaissance)
На этом этапе происходит сбор общедоступной информации о банке и его информационных активах. В частности, злоумышленник пытается определить организационную структуру компании, используемый стек технологий, средства обеспечения ИБ, возможности применения методов социальной инженерии по отношению к сотрудникам. Последний пункт может включать сбор информации на форумах и в социальных сетях, особенно профессиональных.
2. Выбор способа атаки (Weaponization)
Собрав данные, злоумышленники выбирают способ атаки и подбирают подходящий инструментарий. При этом может быть создано новое вредоносное ПО или использовано уже существующее, позволяющее воспользоваться обнаруженными брешами в защите. На этом же этапе происходит выбор способа доставки этого ПО.
3. Доставка (Delivery)
Для доставки приготовленного зловреда используются вложения электронной почты, вредоносные и фишинговые ссылки, watering hole-атаки (заражения сайтов, которые посещают сотрудники атакуемой организации) или зараженные USB-устройства. В нашем примере киберпреступники использовали spear phishing – разослали выбранным сотрудникам банка электронные письма от имени финансового регулятора, Центрального банка Российской Федерации (Банка России). В письме содержался PDF-документ, использующий уязвимость в Adobe Reader.

4. Эксплуатация (Exploitation)
В случае успеха, например, если сотрудник открыл вложение из присланного ему письма, эксплойт пользуется имеющейся уязвимостью и загружает полезную нагрузку (payload). Как правило, это инструменты, необходимые для осуществления дальнейших этапов атаки. В нашем примере устанавливался троянец-загрузчик, который при следующем включении компьютера скачивал бота с сервера злоумышленников.
В случае неудачи злоумышленники, как правило, не бросают начатое, а отступают на один или несколько шагов назад с целью сменить вектор атаки или используемое вредоносное ПО.
5. Установка (Installation)
Вредоносное ПО осуществляет заражение компьютера таким образом, чтобы не быть обнаруженным или удаленным после перезагрузки или установки обновления. Например, упомянутый выше троянец-загрузчик прописывает себя в автозагрузку Windows, туда же он добавляет и бота. При следующих запусках зараженного ПК троянец проверяет наличие бота в системе и, при необходимости, загружает его повторно.
Бот, в свою очередь, постоянно присутствует в памяти компьютера. А чтобы не вызывать у пользователя подозрений, он маскируется под известное системное приложение, например, lsass.exe (Local Security Authentication Server).

6. Исполнение команд (Command and control)
На этом этапе вредоносное ПО ждет команд от атакующих. Наиболее распространенный способ их получения – установка соединения с принадлежащим злоумышленникам C&C-сервером. Именно так поступил бот в нашем примере; при первом обращении к C&C-серверу он получил команду на дальнейшее распространение (Lateral movement) и начал подключаться к другим компьютерам внутри корпоративной сети.
Если зараженные компьютеры не имеют прямого доступа в интернет и не могут обеспечить прямое подключение к C&C-серверу, злоумышленник может прислать на зараженную машину другое ПО, развернуть прокси-сервер в сети организации или заражать физические носители для преодоления «воздушного зазора» (air gap).
7. Достижение цели (Actions on objective)
Теперь злоумышленники могут работать с данными на скомпрометированном компьютере: копировать их, изменять или удалять. Кроме того, если нужная информация не была найдена, атакующие могут попытаться заразить другие машины, чтобы увеличить объем доступной информации или получить дополнительные сведения, позволяющие добраться до приоритетной цели.
Бот в нашем примере заражал другие ПК в поисках машины, с которой осуществляется вход от имени Администратора. После ее обнаружения бот обратился к C&C для загрузки на машину программы Mimikatz и средства удаленного администрирования Ammyy Admin.

Пример выполнения программы Mimikatz. В открытом виде выводятся все логины и пароли, в том числе пароли пользователей Active Directory.
В случае успеха бот может подключиться к ATM Gateway и произвести атаку на банкоматы. Например, внедрить в банкоматы программу, которая будет выдавать деньги при обнаружении специальной пластиковой карты.
Завершающим этапом атаки является удаление и сокрытие следов вредоносного ПО в зараженных системах, но обычно эти мероприятия не включают в kill chain.
Отметим, что эффективность расследования инцидента и размер как материального, так и репутационного ущерба, нанесённого пострадавшей организации, напрямую зависят от того, на каком из перечисленных выше этапов была обнаружена атака.
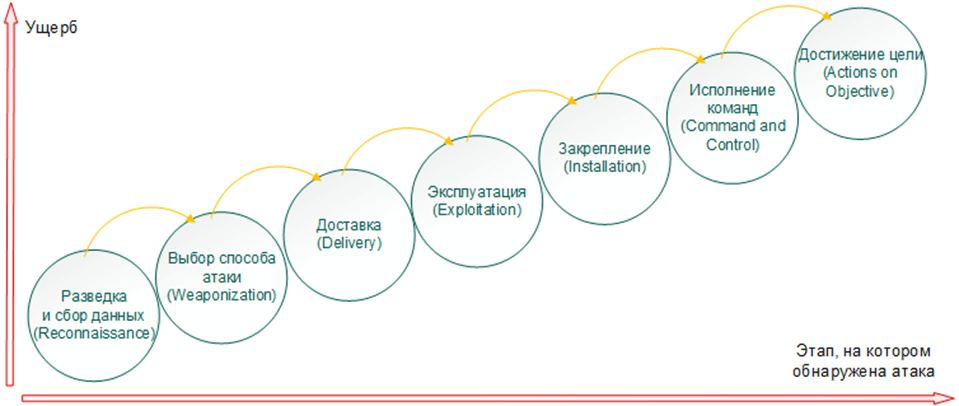
Обнаружение на этапе достижения преступниками цели (позднее обнаружение) означает, что служба информационной безопасности оказалась неспособна противостоять атаке. В этом случае пострадавшей компании стоит пересмотреть свой подход к обеспечению ИБ.
Моя сеть – моя крепость
Мы рассмотрели этапы целевой атаки со стороны киберпреступников – теперь посмотрим, как она выглядит со стороны сотрудников ИБ-службы атакуемой компании. Базовые принципы работы специалистов ИБ, по сути, аналогичны: тщательная подготовка и поэтапная стратегия. Но их действия и используемые инструменты, разумеется, кардинально отличаются, ведь цели перед сотрудниками ИБ стоят совсем другие, а именно:
- Уменьшение ущерба от атаки;
- Максимально быстрое восстановление исходного состояния ИС;
- Создание инструкций по недопущению подобных инцидентов в будущем.
Эти цели достигаются на двух основных этапах – расследования инцидента и восстановления системы. При расследовании требуется определить:
- Начальный вектор атаки;
- Вредоносное ПО, эксплойты и другие средства, используемые атакующими;
- Цель атаки (затронутые сети, системы и данные);
- Размеры ущерба (в том числе репутационного), нанесенного организации;
- Стадию атаки (завершена она или нет, достигнуты ли цели);
- ВременнЫе рамки (начало и конец атаки, время ее обнаружения и время реагирования службы ИБ).
После завершения расследования необходимо разработать и внедрить план восстановления системы, используя полученную при расследовании информацию.
Вернемся к поэтапной стратегии. В общем виде защитная стратегия реагирования на инциденты выглядит следующим образом:
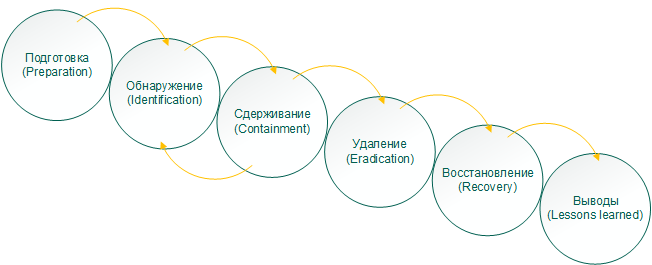
Фазы реагирования на инцидент
По аналогии с этапами целевой атаки, рассмотрим подробнее каждую фазу защиты от нее.
1. Подготовка (Preparation)
В общем смысле предварительная подготовка включает формирование процессов и политик, подбор инструментария. В первую очередь это создание многоуровневой системы защиты, способной противостоять злоумышленникам, использующим несколько векторов атаки. В целом уровни защиты можно разделить на две группы.
Первая включает установку средств, предназначенных для предотвращения атак (Prevention):
- защитных решений для рабочих станций;
- системы обнаружения и предотвращения вторжений (IDS/IPS);
- сетевого экрана для защиты интернет-шлюза;
- прокси-сервера для контроля доступа в интернет.
Вторая группа состоит из решений для обнаружения угроз (Detection):
- SIEM-система с интегрированной информационной сводкой об угрозах отслеживает происходящие в ИС события;
- Система противодействия APT-атакам сопоставляет данные об обнаруженных угрозах, поставляемые различными механизмами безопасности;
- Ловушка (honeypot) — специальный ложный объект для кибератак, который изолирован и находится под тщательным наблюдением службы ИБ;
- EDR-системы (инструменты распознавания и реагирования на угрозы на конечных устройствах) повышают информированность о событиях, происходящих на конечных устройствах, и дают возможность автоматического сдерживания и ликвидации угроз.
Организация, атаку на которую мы взяли в качестве примера, была готова к неожиданностям. Банкоматы были отделены от основной сети банка, доступ в подсеть был разрешен только отдельным пользователям.

Сеть организации, подвергшейся атаке
Для отслеживания и анализа происходящих в сети событий использовалась SIEM-система, которая собирала:
- информацию о сетевых соединениях на прокси-сервере, который использовался всеми сотрудниками для доступа в интернет;
- интегрированные потоки данных об угрозах, предоставленные специалистами «Лаборатории Касперского»;
- уведомления о письмах, прошедших через почтовый сервер Postfix, в том числе информацию о заголовках, DKIM-подписи и т.д.
Также в SIEM попадала вся информация о срабатывании защитного решения на любой рабочей станции в IT-инфраструктуре организации.
Другой важный элемент подготовки – проведение тестирования на возможность проникновения, чтобы предсказать (Predict) возможный вектор кибератаки. Смоделировать проникновение в сеть компании можно как своими силами, так и с привлечением сторонних организаций. Последний вариант более затратный, но предпочтительный – организации, специализирующиеся на пен-тестах, как правило, обладают обширным опытом и лучше осведомлены об актуальных векторах угроз.
И наконец, последний, но не менее важный элемент – это информирование сотрудников организации. Оно включает внутренние тренинги по ИБ для всех сотрудников – они должны быть в курсе политик безопасности и знать, что нужно делать в случае кибератаки. Сюда же относится целевое обучение специалистов, ответственных за безопасность компании, а также накопление информации об инцидентах ИБ, случившихся в компании и вне ее. Источником таких сведений могут быть внутренние отчеты компании и сервисы сторонних организаций, специализирующихся на исследовании киберугроз – например, Kaspersky Threat Intelligence Portal.
2. Обнаружение (Identification)
На этом этапе необходимо определить, является ли инцидент таковым на самом деле. Только после этого можно объявлять «Нас атакуют!» и поднимать тревогу среди коллег. Для определения факта инцидента используются так называемые триггеры – события, свидетельствующие о кибератаке. К ним относятся попытки рабочей станции связаться с известным вредоносным C&C, ошибки и отказы в работе защитного ПО, неожиданное изменение прав пользователя, присутствие в сети организации неизвестных программ и многое другое.
Информация об этих событиях может поступать из различных источников. Здесь мы рассмотрим два ключевых типа триггеров:
- Триггеры, генерируемые системами управления защитой конечных устройств (EPP management system). Когда защитное решение на одной из рабочих станций обнаруживает угрозу, оно генерирует событие и отсылает его системе управления. Но не все такие события являются триггерами: например, за событием, свидетельствующим об обнаружении вредоносной программы, может следовать событие о ее обезвреживании. В таком случае расследование не нужно, за исключением случаев, когда ситуация регулярно повторяется на одной и той же машине или у одного и того же пользователя.
- Триггеры инцидентов, генерируемые SIEM-системами. SIEM-системы могут накапливать данные, поступающие с очень большого количества средств контроля безопасности, в том числе с прокси-серверов и межсетевых экранов. Триггерами могут считаться лишь те события, которые создаются в результате сопоставления поступивших данных с информационной сводкой об угрозах.
Для определения инцидента имеющаяся в распоряжении службы ИБ информация сравнивается со списком известных индикаторов заражения (IoC). Для этих целей могут использоваться публичные отчеты, потоки данных об угрозах, средства статического и динамического анализа образцов и др.
Статический анализ выполняется без непосредственного запуска исследуемого образца и заключается в сборе различных индикаторов, таких как строки, содержащие URL или адрес электронной почты, и др. Динамический анализ подразумевает выполнение исследуемой программы в защищенной среде («песочнице») или на изолированной машине с целью выявления поведения образца и сбора индикаторов заражения.

Цикл обнаружения индикаторов заражения
Как видно из рисунка выше, сбор IoC является циклическим процессом. На основе первоначальной информации, полученной от SIEM-системы, происходит формирование сценариев обнаружения, применение которых, как правило, приводит к выявлению новых индикаторов заражения.
Вот, например, как могут использоваться потоки данных об угрозах для определения spear phishing атаки, в нашем случае – письма с вложенным PDF-документом, использующим уязвимость в Adobe Reader.
- IP-адрес сервера, отправившего сообщение электронной почты, будет детектирован SIEM по IP Reputation Data Feed.
- Запрос на загрузку бота будет детектирован SIEM по Malicious URL Data Feed.
- Обращение к серверу управления (C&C) будет детектировано SIEM по Botnet C&C URL Data Feed.
- Mimikatz будет обнаружен и удален защитным решением для рабочих станций, информация об обнаружении попадет в SIEM.
Таким образом, на ранней стадии атака может быть обнаружена четырьмя различными способами. Компания при этом понесет минимальный ущерб.
3. Сдерживание (Containment)
Предположим, что из-за высокой загруженности ИБ-служба не смогла отреагировать на первые оповещения, и к моменту начала реагирования атака успела дойти до шестого этапа, т.е. вредоносное ПО успешно проникло на компьютер в сети организации и попыталось связаться с C&C, а система SIEM получила событие.
В этом случае сотрудники ИБ должны идентифицировать скомпрометированные компьютеры и изменить правила безопасности таким образом, чтобы заражение не распространилось по сети. Кроме того, нужно перенастроить информационную систему, чтобы она могла обеспечить работу компании без участия зараженных машин. Рассмотрим каждое из этих действий подробнее.
Изоляция скомпрометированных компьютеров
Взломанные компьютеры необходимо выявить – например, найдя в SIEM все обращения к известному адресу C&C, – а затем поместить в изолированную сеть. При этом политика маршрутизации должна быть изменена так, чтобы исключить коммуникацию между скомпрометированными компьютерами и другими компьютерами корпоративной сети, а также подключение скомпрометированных компьютеров к интернету.
Дополнительно рекомендуется проверить адрес C&C с помощью специального сервиса, например, Threat Lookup. В результате можно получить не только хэши программ-ботов, которые взаимодействовали с этим C&C, но также другие адреса, с которыми взаимодействовали эти боты. После этого стоит повторить поиск в SIEM по расширенному списку индикаторов, так как один и тот же бот мог взаимодействовать с несколькими C&C на разных компьютерах. Все выявленные таким образом зараженные рабочие станции должны быть изолированы и исследованы.
При этом скомпрометированные компьютеры лучше не выключать, так как это может усложнить расследование. В частности, некоторые виды вредоносных программ используют только оперативную память компьютера, не создавая файлов на жестком диске. Другие зловреды могут удалить IoC при получении системой сигнала отключения.
Также не рекомендуется отключать (прежде всего физически) локальные сетевые соединения пострадавших ПК. Некоторые виды вредоносных программ отслеживают состояние подключения, и, если соединение не было доступно в течение определенного времени, зловред может начать удалять следы своего присутствия на компьютере, уничтожая IoC. В то же время имеет смысл ограничить доступ зараженных машин к внутренней и внешней сети (например, заблокировать пересылку пакетов с помощью iptables).
Более подробную информацию о том, что делать, если поиск по адресу C&C не дал существенных результатов, а также о том, как выявить вредоносное ПО, можно найти в полной версии данного руководства.
Создание дампов памяти и дампов жесткого диска
Анализируя дампы памяти и дампы жесткого диска скомпрометированных компьютеров, можно получить образцы вредоносного ПО и IoC, связанные с атакой. Исследование этих образцов позволяет понять, как следует бороться с заражением, и определить вектор распространения угрозы, чтобы не допустить повторного заражения по аналогичному сценарию в будущем. Собрать дампы поможет специальное ПО, например, Forensic Toolkit.
Поддержание работоспособности системы
После изоляции скомпрометированных компьютеров следует принять меры по сохранению работоспособности информационной системы. Например, если в корпоративной сети было взломано несколько серверов, необходимо внести такие изменения в политику маршрутизации, чтобы нагрузка на скомпрометированные серверы была перенаправлена на другие серверы.
4. Удаление (Eradication)
Цель данного этапа – привести скомпрометированную информационную систему в состояние, в котором она находилась до атаки. Сюда входит удаление вредоносного ПО и всех артефактов, которые оно могло оставить на зараженных компьютерах, а также восстановление исходной рабочей конфигурации ИС.
Для этого имеются две возможные стратегии: полная переустановка ОС скомпрометированного устройства или простое удаление вредоносного ПО. Первый вариант подходит для организаций, использующих стандартный набор ПО для рабочих станций. В этом случае восстановить работоспособность последних можно с помощью образа системы. Мобильные телефоны и прочие устройства можно сбросить к заводским настройкам.
Во втором случае артефакты, созданные вредоносным ПО, можно обнаружить, проведя анализ с помощью специализированных инструментов и утилит. Подробнее об этом вы можете узнать в полной версии нашего руководства.
5. Восстановление (Recovery)
На этом этапе ранее скомпрометированные компьютеры вводятся обратно в сеть. При этом сотрудники ИБ некоторое время продолжают наблюдать за состоянием этих машин, чтобы убедиться в полном устранении угрозы.
6. Выводы (Lessons learned)
По завершении расследования служба безопасности должна составить отчет, содержащий ответы на следующие вопросы:
- Когда и кем был обнаружен инцидент?
- Каков масштаб инцидента? Какие объекты были затронуты инцидентом?
- Как были выполнены этапы «Сдерживание», «Удаление», «Восстановление»?
- На каких этапах реагирования на инцидент действия сотрудников ИБ нуждаются в коррекции?
На основании отчета и информации, полученной при расследовании, необходимо разработать меры для предотвращения подобных инцидентов в будущем. В их число может быть включена коррекция политик безопасности, изменение конфигурации ресурсов организации, проведение тренингов по безопасности для сотрудников и т.д. Индикаторы заражения, полученные в процессе реагирования на инцидент, могут в будущем использоваться для обнаружения других атак такого рода.
В порядке очереди
Случается, что инцидент – как беда – не приходит в одиночестве, и в результате сотрудники службы ИБ вынуждены реагировать на несколько инцидентов одновременно. В такой ситуации очень важно, не теряя времени, правильно расставить приоритеты и сосредоточиться на основных угрозах – именно это позволит минимизировать потенциальный ущерб от атаки.
Мы рекомендуем определять степень важности инцидента, исходя из следующих факторов:
- Сегмент сети, где находится взломанный ПК;
- Ценность данных, хранимых на взломанном компьютере;
- Тип и количество других инцидентов, затронувших тот же ПК;
- Достоверность индикатора заражения, соответствующего данному инциденту.
Следует отметить, что выбор того, какой сервер или сегмент сети спасать первым, а какой рабочей станцией можно пожертвовать, зависит от специфики организации.
Если события, поступившие от одного из источников, включают IoC, опубликованные в одном из отчетов по APT-угрозам, или факты взаимодействия с C&C-сервером, ранее использовавшимся при проведении APT-атаки, то именно эти инциденты мы рекомендуем рассматривать в первую очередь. Помочь в этом могут инструменты и утилиты, описанные в полной версии нашего «Руководства по реагированию на инциденты».
Заключение
В рамках одной публикации невозможно рассмотреть весь арсенал, которым располагают современные киберпреступники, описать все существующие векторы атаки и составить пошаговую инструкцию по реагированию на любые подобные инциденты для сотрудников службы ИБ. Более того, для решения этой задачи может не хватить даже целой серии статей – настолько сложными и разнообразными стали современные APT-атаки. Однако надеемся, что изложенные нами рекомендации по выявлению инцидентов и реагированию на них помогут сотрудникам служб информационной безопасности создать прочный фундамент для надежной многоуровневой защиты бизнеса.
Реакция нейтрализации
Содержание
- Планы наступления
- 1. Разведка и сбор данных (Reconnaissance)
- 2. Выбор способа атаки (Weaponization)
- 3. Доставка (Delivery)
- 4. Эксплуатация (Exploitation)
- 5. Установка (Installation)
- 6. Исполнение команд (Command and control)
- 7. Достижение цели (Actions on objective)
- Моя сеть – моя крепость
- 1. Подготовка (Preparation)
- 2. Обнаружение (Identification)
- 3. Сдерживание (Containment)
- Изоляция скомпрометированных компьютеров
- Создание дампов памяти и дампов жесткого диска
- Поддержание работоспособности системы
- 4. Удаление (Eradication)
- 5. Восстановление (Recovery)
- 6. Выводы (Lessons learned)
- В порядке очереди
- Заключение
От тех же авторов





В той же категории











Игорь
А ещё можно отслеживать такое событие: пошли платежи по реквизитам ЮЛ, которые отсутствуют в БД наших контрагентов. Тогда негодяям потребуется вломиться в базу 1С и создать там соответствующих юриков. А это уже — не текстовый файл поменять.