

Авторы
Риски для контейнеризованных сред
Контейнеры обеспечивают изолированность среды выполнения для приложений, однако уровень этой изоляции часто переоценивают. Хотя контейнеры включают все необходимые зависимости и обеспечивают единообразие среды, они все равно обращаются к ядру системы хоста, что создает определенные риски для безопасности.
В рамках оказания услуг по оценке компрометации (Compromise Assessment), консалтингу SOC и реагированию на инциденты мы неоднократно сталкивались с проблемами, связанными с отсутствием видимости контейнеров. Многие организации сосредотачиваются на мониторинге контейнеризованных сред для оценки их работоспособности, а не для выявления угроз безопасности. Некоторым компаниям не хватает опыта для правильной настройки ведения журналов, а другие используют технологические стеки, которые не обеспечивают полноценной видимости работающих контейнеров.
Среды с ограниченной видимостью затрудняют работу специалистов по киберугрозам и реагированию на инциденты, поскольку в них сложно однозначно отличить процессы, запущенные внутри контейнера, от тех, что выполняются непосредственно на хосте. Из-за этой неопределенности трудно установить, откуда на самом деле началась атака — в скомпрометированном контейнере или непосредственно на хосте.
В этой статье мы разбираемся, как восстановить цепочку выполнения процессов внутри работающего контейнера на основе логов хоста. Описанные методы помогут специалистам по киберугрозам и реагированию на инциденты определять первопричину компрометации исключительно на основе логов, собранных на уровне хоста.
Как создаются контейнеры и как они работают
Чтобы эффективно расследовать инциденты безопасности и выявлять угрозы в контейнеризованных средах, важно понимать, как создаются контейнеры и как они работают. В отличие от виртуальных машин, в которых запускаются отдельные операционные системы, контейнеры — это изолированные пользовательские пространства, использующие ядро операционной системы хоста. Они полагаются на пространства имен (namespaces), контрольные группы (cgroups), объединенные файловые системы (union filesystems), механизм разграничения прав (capabilities) и другие функции Linux для управления ресурсами и обеспечения изоляции.
Такая архитектура означает, что каждый процесс внутри контейнера технически выполняется на хосте, но в отдельном пространстве имен. Специалисты по киберугрозам и реагированию на инциденты обычно проводят ретроспективный анализ логов на уровне хоста, чтобы изучать запущенные процессы и аргументы командной строки в тех случаях, когда в инфраструктуре не предусмотрены специализированные решения для мониторинга контейнерной среды. Однако в некоторых конфигурациях журналов могут не учитываться критически важные атрибуты, в том числе пространства имен, cgroups или определенные системные вызовы. В таких ситуациях стоит не зацикливаться на отсутствующих в логах атрибутах, а компенсировать этот пробел в видимости, анализируя цепочку выполнения процессов внутри работающего контейнера с точки зрения хоста.

Порядок создания контейнеров
Конечные пользователи создают контейнеры и управляют ими с помощью таких утилит командной строки, как Docker CLI, kubectl и других. Эти утилиты обращаются к движку, который обменивается данными с высокоуровневой средой выполнения контейнеров — чаще всего это containerd или CRI-O. Высокоуровневые среды выполнения используют низкоуровневые, преимущественно runc, чтобы взаимодействовать с ядром операционной системы Linux — выделять cgroups, пространства имен и т. д. — для создания и удаления контейнеров на основе бандла, предоставленного высокоуровневой средой выполнения, которая, в свою очередь, формируется из аргументов, заданных пользователем. Бандл (bundle) — это самостоятельный каталог, определяющий конфигурацию контейнера в соответствии со спецификацией среды выполнения Open Container Initiative (OCI). Он в основном включает следующее.
- Каталог rootfs, выступающий в роли корневой файловой системы контейнера. Он создается путем извлечения и объединения слоев образа контейнера, как правило, с помощью объединенной файловой системы, например OverlayFS.
- Файл config.json с описанием конфигурации среды выполнения OCI — в нем задаются параметры процесса, точки монтирования и другие настройки, необходимые для создания контейнера.
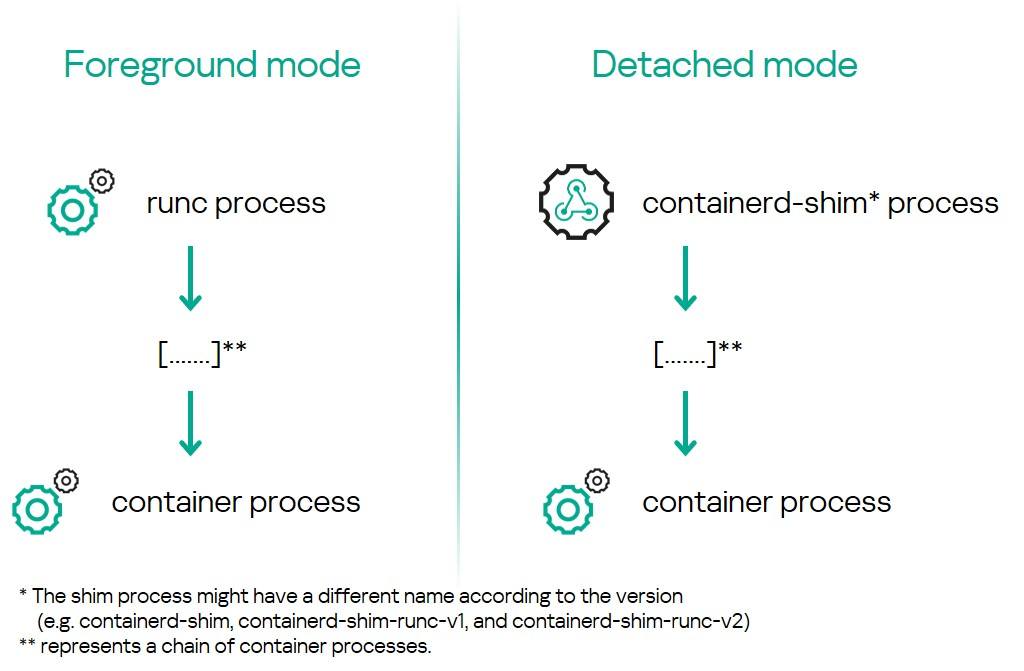
Важно учитывать, в каком режиме был запущен runc, так как он поддерживает два: интерактивный (foreground/interactive) и фоновый (detached), — и итоговое дерево процессов может отличаться в зависимости от выбранного режима. В интерактивном режиме процесс runc будет длительно работать на переднем плане в качестве родительского процесса контейнерного процесса — главным образом для обработки ввода-вывода (stdio), чтобы конечный пользователь мог взаимодействовать с работающим контейнером.

Дерево процессов контейнера, созданного в интерактивном режиме с помощью runc
С другой стороны, в фоновом режиме (detached mode) процесс runc не остается на длительное выполнение. После создания контейнера runc завершает работу, передавая обработку ввода-вывода вызывающему процессу — чаще всего containerd или CRI-O. Как видно на приведенном ниже снимке экрана, при запуске контейнера в фоновом режиме с помощью runc процесс создает контейнер и сразу завершается. В результате родительским процессом контейнера становится процесс с PID 1 (обычно systemd) на хосте.
Дерево процессов контейнера, созданного в фоновом режиме с помощью runc
Однако если создать контейнер в фоновом режиме с помощью Docker CLI, то родительским процессом контейнера окажется не процесс с PID 1, а специальный shim-процесс.

Дерево процессов контейнера, созданного в фоновом режиме с помощью Docker CLI
В современных архитектурах взаимодействие между высокоуровневой и низкоуровневой контейнерными средами выполнения происходит через прослойку в виде shim-процесса. Он позволяет контейнерам работать независимо от высокоуровневой среды выполнения, обеспечивая их стабильность даже при сбое или перезапуске этой среды. Shim-процесс также управляет стандартным вводом-выводом (stdio) контейнерного процесса, благодаря чему пользователи могут подключаться к работающим контейнерам с помощью таких команд, как docker exec -it <container>. Кроме того, он способен перенаправлять stdout и stderr в лог-файлы, которые затем можно просматривать напрямую через файловую систему или с помощью команд вроде
Когда через Docker CLI создается контейнер в фоновом режиме, высокоуровневая среда выполнения контейнеров, например containerd, порождает shim-процесс, который вызывает низкоуровневую среду выполнения (runc), единственное назначение которой — запустить контейнер в фоновом режиме. После этого runc сразу завершает работу. Чтобы избежать появления «осиротевших» процессов или установления процесса с PID 1 (init) в качестве родителя, как это происходит при прямом запуске runc, shim-процесс явно назначает себя «усыновителем» (subreaper), чтобы взять под свое крыло процессы контейнера после завершения работы runc. В среде Linux процесс subreaper выполняет роль назначенного родителя для «осиротевших» дочерних процессов, принимая их в свою цепочку вместо процесса init, что позволяет ему управлять всем деревом процессов и корректно его завершать.
Так это реализовано в shim V2 — последней и используемой по умолчанию версии в современных реализациях containerd.
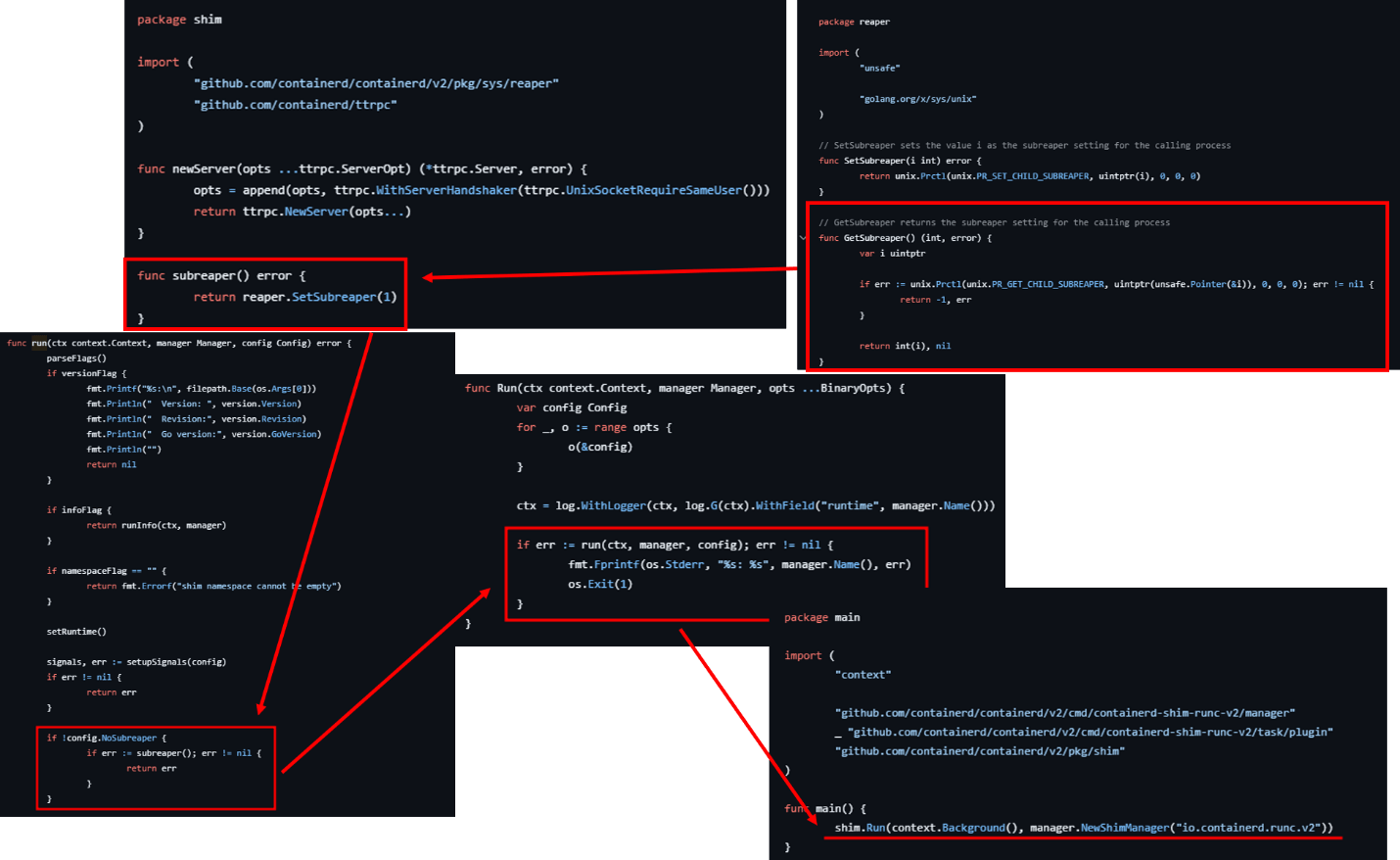
При создании shim-процесс берет на себя роль «усыновителя» (subreaper)
Согласно справочному сообщению процесса containerd-shim-runc-v2, он принимает идентификатор контейнера в качестве аргумента командной строки, называя его id of the task (идентификатор задачи).
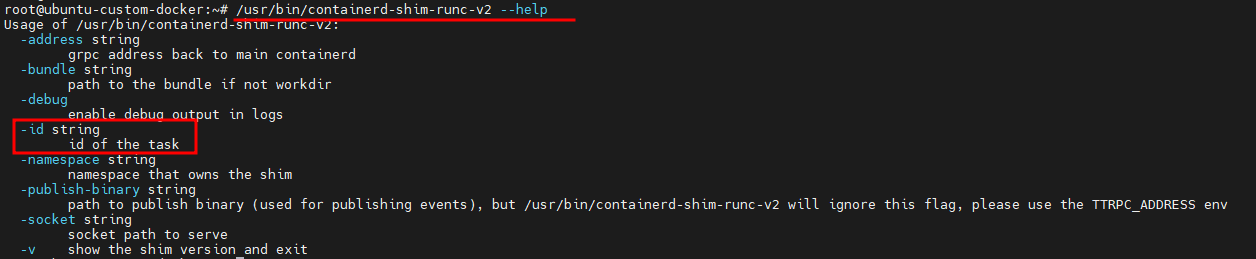
Справочное сообщение shim-процесса
В этом можно убедиться, проверив аргументы командной строки запущенных процессов containerd-shim-runc-v2 и сопоставив их с работающими контейнерами.

Shim-процесс принимает в качестве аргумента ID соответствующего контейнера
Теперь у нас есть представление о том, как можно идентифицировать процессы контейнера с точки зрения хоста. В современных архитектурах в роли родительского процесса для контейнерных процессов обычно выступает один из следующих вариантов:
- shim — при запуске в фоновом режиме (detached);
- runc — при запуске в интерактивном режиме (foreground/interactive).
Также можно изучить аргументы командной строки shim-процесса, чтобы определить, к какому контейнеру он принадлежит.
Дерево процессов контейнеров с точки зрения хоста
Отслеживание дочерних процессов shim-процесса иногда дает быстрые результаты, но зачастую все куда сложнее, особенно когда между shim-процессом и зловредным процессом находится множество промежуточных процессов. В таких случаях нужно двигаться «снизу вверх» от зловредного процесса к его родителям вплоть до shim-процесса, чтобы подтвердить, что он был запущен внутри работающего контейнера. В этом контексте важно правильно выбрать процесс, поведение которого необходимо проверить на наличие вредоносной или подозрительной активности.
Контейнеры обычно работают с минимальным набором зависимостей, поэтому злоумышленники часто пытаются получить доступ к оболочке — либо для прямого выполнения команд, либо для установки недостающих зависимостей для своего вредоносного ПО. Поэтому при выявлении атак следует уделять особое внимание оболочкам контейнеров. Но как именно ведут себя эти оболочки? Давайте подробнее рассмотрим один из основных процессов оболочки в контейнеризованных средах.
Как BusyBox и Alpine выполняют команды
В этом материале мы сосредоточились на поведении контейнеров, основанных на наборе утилит BusyBox. Также в качестве примера базового образа, где для компактности многие основные утилиты Linux реализованы с помощью BusyBox, мы используем контейнеры на базе Alpine. Для наглядности в статье не рассматриваются Alpine-образы, зависящие от других утилит.
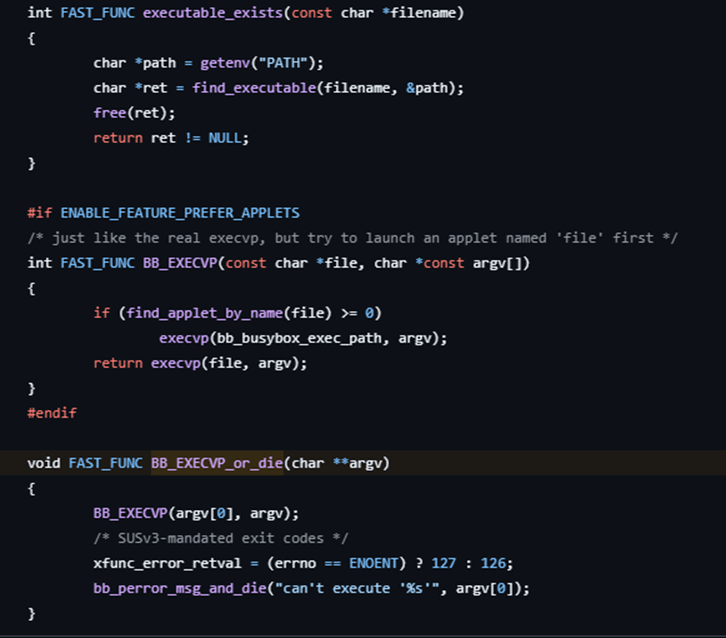
BusyBox предоставляет минималистичные аналоги многих часто используемых UNIX-утилит, объединенные в один небольшой исполняемый файл. Это позволяет создавать легкие контейнеры с существенно уменьшенным размером образа. Но как на самом деле работает исполняемый файл BusyBox?
BusyBox реализует собственные версии системных утилит, которые называются апплетами. Каждый апплет написан на языке C и хранится в исходном коде в каталоге busybox/coreutils/. Например, UNIX-утилита cat имеет собственную реализацию в файле cat.c. Во время выполнения BusyBox создает таблицу апплетов, в которой имена апплетов сопоставлены с соответствующими функциями, чтобы определить, какой апплет запускать на основе переданного аргумента командной строки. Этот механизм описан в файле appletlib.c.
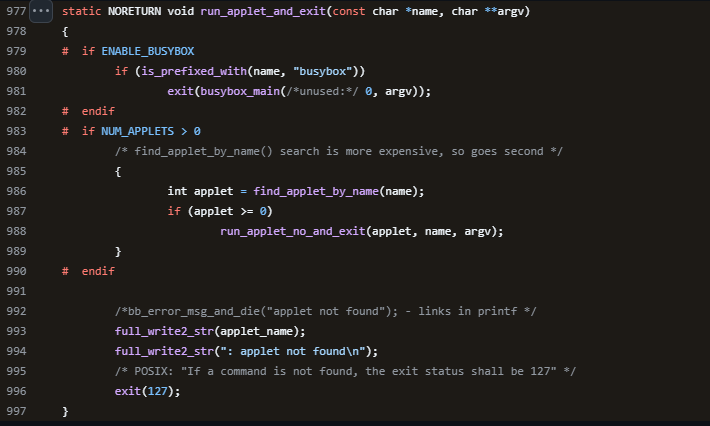
Фрагмент файла appletlib.c
Если выполняемая команда вызывает установленную утилиту, не являющуюся стандартным апплетом BusyBox, ее расположение определяется с помощью переменной окружения PATH. После определения пути BusyBox запускает эту утилиту как дочерний процесс своего процесса. Нужно обязательно знать об этом механизме динамического выполнения, чтобы понимать, как выполняются команды внутри контейнера на базе BusyBox.
Логика выполнения апплета/программы
Теперь, когда мы имеем четкое представление о работе исполняемого файла BusyBox, давайте рассмотрим, как он функционирует внутри контейнера. Например, что происходит при выполнении команды sh в таких контейнерах?
В контейнерах на базе BusyBox и Alpine при обращении к оболочке с помощью команды sh на самом деле не запускается отдельный исполняемый файл с именем sh. Вместо этого выполняется сам исполняемый файл BusyBox. Имея под рукой контейнер BusyBox, можно убедиться, что /bin/sh заменен на BusyBox, сравнив inode файлов /bin/sh и /bin/busybox с помощью команды ls -li, — они будут иметь одинаковый номер inode. Также можно вычислить их MD5-хэши — они будут совпадать. При запуске команды /bin/sh --help будет отображен баннер BusyBox, что подтверждает вызов именно этого исполняемого файла.
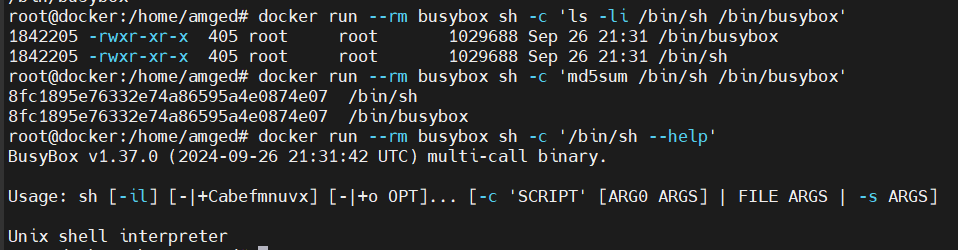
В контейнерах на базе BusyBox вместо исполняемого файла /bin/sh используется /bin/busybox
С другой стороны, в контейнерах на базе Alpine файл /bin/sh является символической ссылкой на /bin/busybox. То есть при выполнении команды sh фактически запускается исполняемый файл BusyBox, на который указывает эта ссылка. Чтобы это подтвердить, достаточно посмотреть результат выполнения команды readlink -f /bin/sh.

В контейнерах на базе Alpine /bin/sh — это символическая ссылка на /bin/busybox
В итоге внутри контейнеров на базе BusyBox или Alpine все команды оболочки либо выполняются напрямую самим процессом BusyBox, либо запускаются как его дочерние процессы. Эти процессы работают в изолированных пространствах имен в операционной системе хоста, что обеспечивает контейнеризацию при использовании общего ядра хоста.
С точки зрения поиска угроз необходимо отдельно расследовать случаи появления нестандартного для данной ОС процесса оболочки, такого как BusyBox. Например, запуск процесса оболочки BusyBox был бы нетипичным в системе Debian или RedHat. В этом случае мы можем выяснить, была ли запущена оболочка внутри контейнера, — для этого достаточно убедиться, что родительским процессом BusyBox является процесс runc или shim. Этот же принцип применим не только к процессу BusyBox, но и к любому другому процессу, запущенному внутри работающего контейнера. Только понимая этот принцип, можно эффективно выявить источник подозрительного поведения при анализе логов процессов на хосте.
Некоторые средства безопасности, такие как Kaspersky Container Security, специально разрабатывались для отслеживания активности и выявления подозрительного поведения внутри контейнеров. Другие решения, например Auditd, предоставляют расширенные возможности ведения журналов на уровне ядра на основе заранее определенных правил, которые фиксируют системные вызовы, доступ к файлам и действия пользователей. Однако такие правила часто не адаптированы к контейнеризованным средам, из-за чего становится сложнее разграничить активность на хосте и внутри контейнера.
Примеры из реальных расследований
Во время анализа логов выполнения специалисты по киберугрозам и реагированию на инциденты не заостряют внимания на некоторых событиях в среде Linux, принимая их за нормальное поведение системы. Однако те же действия, выполненные внутри работающего контейнера, должны вызывать подозрение. Например, установка некоторых утилит, таких как Docker CLI, может быть приемлемой для хоста, но не для контейнера. Недавно в рамках проекта по оценке компрометации мы выявили кампанию по майнингу криптовалют, в которой злоумышленники установили Docker CLI внутри работающего контейнера, чтобы упростить взаимодействие с API демона dockerd.
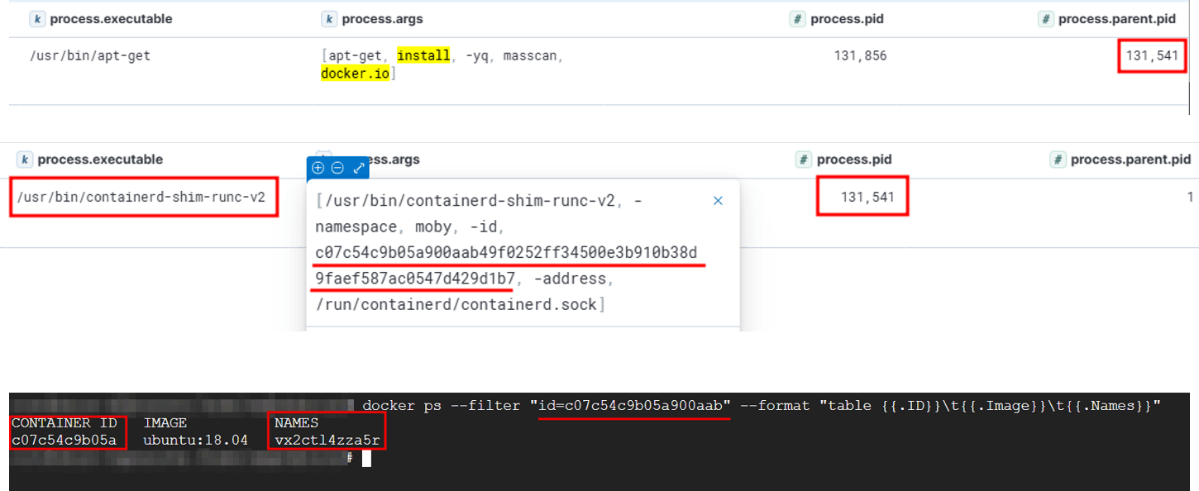
Подтверждение того, что пакет docker.io был установлен внутри работающего контейнера
В этом случае мы отследили цепочку процессов и установили, что Docker CLI был установлен внутри контейнера. Затем мы проверили аргументы командной строки shim-процесса, установили источник выполненной команды и подтвердили контейнер, в котором она была запущена.
Во время другого расследования мы зафиксировали весьма любопытное событие: процесс имел имя systemd, но путь к исполняемому файлу указывал на /.redtail. Мы установили происхождение процесса тем же способом — отслеживанием его родительских процессов.
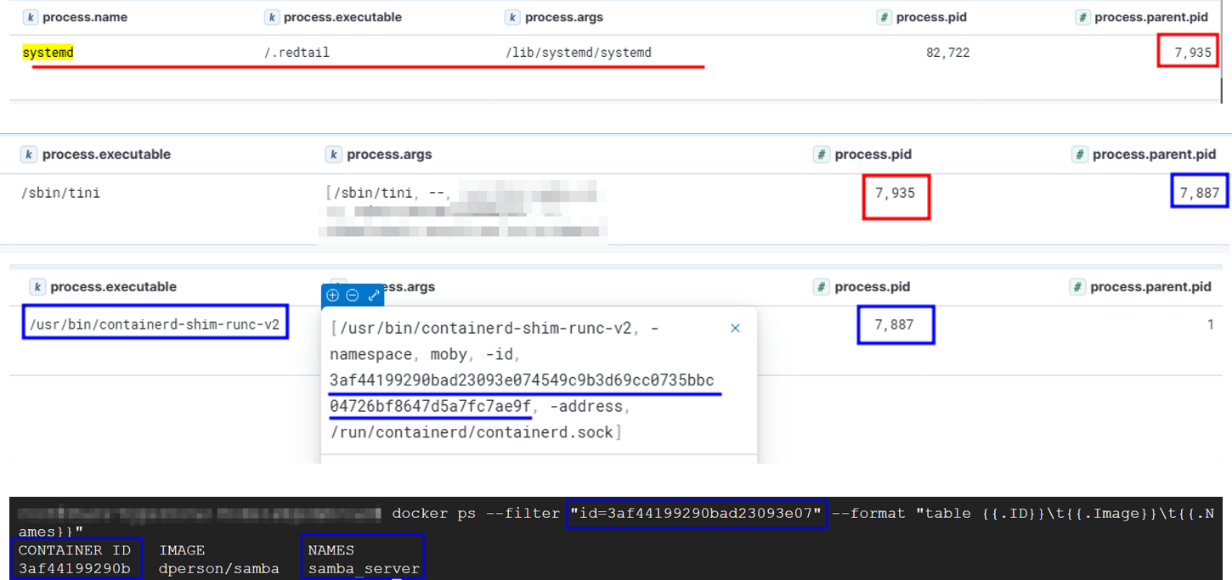
Определение контейнера, в котором произошло подозрительное событие
Еще один интересный факт, который нам может пригодиться: контейнер Docker всегда создается с помощью процесса runc — низкоуровневой среды выполнения контейнеров. В справочном сообщении runc перечислены аргументы командной строки, используемые для создания, запуска или старта контейнеров.
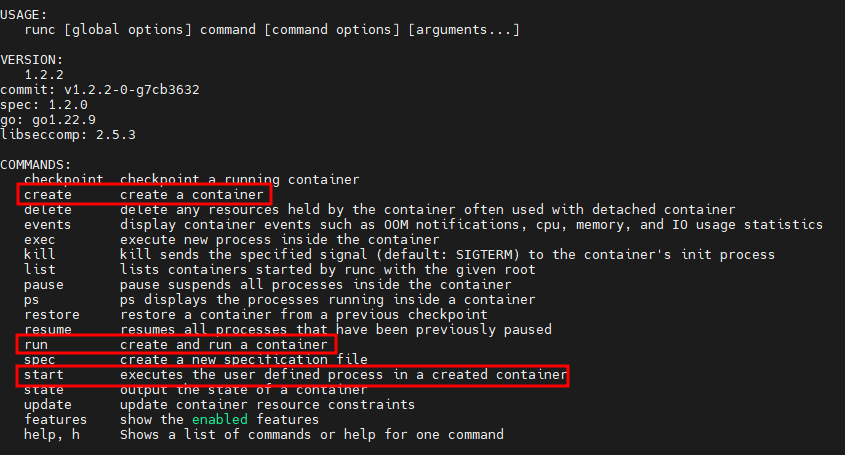
Справочное сообщение runc
Мониторинг событий с такими аргументами помогает специалистам по киберугрозам и реагированию на инциденты определить идентификатор целевого контейнера и обнаружить аномальные точки входа. Точка входа контейнера — это его основной процесс, который будет запущен через runc. На снимке экрана ниже показан пример создания вредоносного контейнера, обнаруженного в ходе активного поиска точек входа по подозрительным аргументам командной строки. В данном случае в командной строке содержится вредоносная команда, закодированная по алгоритму Base64.

Поиск подозрительных точек входа контейнеров
Заключение
На сегодняшний день контейнеризованные среды в той или иной форме присутствуют в большинстве корпоративных сетей благодаря удобству развертывания и решению проблем с зависимостями. Однако команды безопасности и руководство часто разделяют распространенные заблуждения о принципах изоляции контейнеров и недооценивают связанные с ними угрозы. Как следствие, штатные специалисты по безопасности могут не обладать необходимыми знаниями и инструментами для эффективного мониторинга и обнаружения подобных угроз, в том числе реагирования на них, что может привести к компрометации контейнеров.
Изложенные в этой статье сведения являются частью стандартных процедур, применяемых нами при оказании услуг по оценке компрометации и реагированию на инциденты — особенно когда требуется выявить угрозы в исторических логах выполнения на хосте с ограниченной видимостью контейнеров. Тем не менее для своевременного обнаружения угроз, связанных с контейнерами, крайне важно защитить свои системы надежным решением для мониторинга контейнеризованных сред, например Kaspersky Container Security.
От тех же авторов

В той же категории












Анализ логов хоста в контексте контейнерных угроз: как определить точку начала атаки