

Авторы
В этой статье мы представляем ключевые выводы, сделанные на основе проектов Kaspersky Compromise Assessment за 2025 год. Kaspersky Compromise Assessment — это независимый экспертный сервис для выявления признаков компрометации в сетях организаций. В рамках сервиса мы анализируем данные об угрозах (включая сведения из различных источников в даркнете), сканируем конечные устройства специализированными инструментами, осуществляем комплексный анализ логов событий безопасности и сетевого трафика. При необходимости также проводим первичное реагирование на инциденты и криминалистический анализ.
Отчет посвящен инцидентам, которые оставались незамеченными на протяжении нескольких недель, месяцев и даже лет.
Ключевые тенденции, выявленные в завершенных проектах Kaspersky Compromise Assessment
- Поиск следов компрометации (compromise assessment) позволяет снизить количество пропущенных инцидентов высокой критичности. Наибольшая доля высококритичных инцидентов была выявлена в организациях, которые обратились к нам за поиском следов компрометации после локализации уже известного инцидента безопасности. Наименьшая доля инцидентов высокой критичности наблюдалась в организациях, регулярно проводивших аудиты безопасности. Из всех исследованных инцидентов 20% были обнаружены вручную. Около 60% угроз не были замечены организациями из-за отсутствия надежных оповещений от существующих средств защиты.
- Почти треть зафиксированных инцидентов были выявлены более чем через три месяца после первичного проникновения. Чем дольше угроза сохраняла присутствие в целевой среде, тем выше была вероятность того, что инцидент имел высокий уровень критичности. В 30,8% случаев были найдены следы активности злоумышленников, продолжавшейся более трех месяцев, при этом среди заражений высокой критичности таких случаев было 52%. Самый давний инцидент, выявленный нами в 2025 году, оставался незамеченным на протяжении четырех лет.
- Нередко вредоносные файлы сохраняются в резервных копиях и восстанавливаются после принятия мер реагирования на инцидент. Так, 40% обнаруженных веб-шеллов находились в резервных копиях и оставались незамеченными до проведения полноценного поиска следов компрометации.
- Злоумышленники предпочитают инструменты удаленного управления, а также уже установленные легитимные программы (так называемые LOLBins). Подобные инструменты использовались во всех инцидентах, обнаруженных по итогам поиска следов компрометации.
- Наличие средств мониторинга и защиты само по себе недостаточно — решающую роль играет зрелость операционных процессов. Решения для мониторинга необходимо корректно настраивать и адаптировать с учетом постоянно меняющегося ландшафта угроз. При этом оповещения с низким уровнем достоверности должны рассматривать аналитики. Отсутствие непрерывного мониторинга и активного поиска угроз повышало вероятность инцидентов средней и высокой критичности до 84–86%. В то же время инциденты высокого уровня критичности реже встречались в организациях, команды которых обладали навыками реверс-инжиниринга вредоносного ПО.
- Пробелы в коммуникациях приводят к пропуску инцидентов. Почти треть проведенных оценок компрометации выявили коммуникационные пробелы, повлиявшие на эффективность мероприятий по реагированию на инциденты.
- Сценарии реагирования на инциденты должны быть гибкими. Чтобы реагирование было эффективным, сценарии необходимо регулярно пересматривать с учетом появления новых артефактов. Постоянно дорабатывая план реагирования на инциденты, организации снижают вероятность пропуска угроз.
О работе сервиса Kaspersky Compromise Assessment
Услугами нашего сервиса по поиску следов компрометации пользуются компании из разных стран. Около 71% инцидентов, выявленных в 2025 году, пришлось на клиентов в регионе META (Ближний Восток, Турция, Африка), оставшиеся 29% — на Азиатско-Тихоокеанский регион и СНГ.
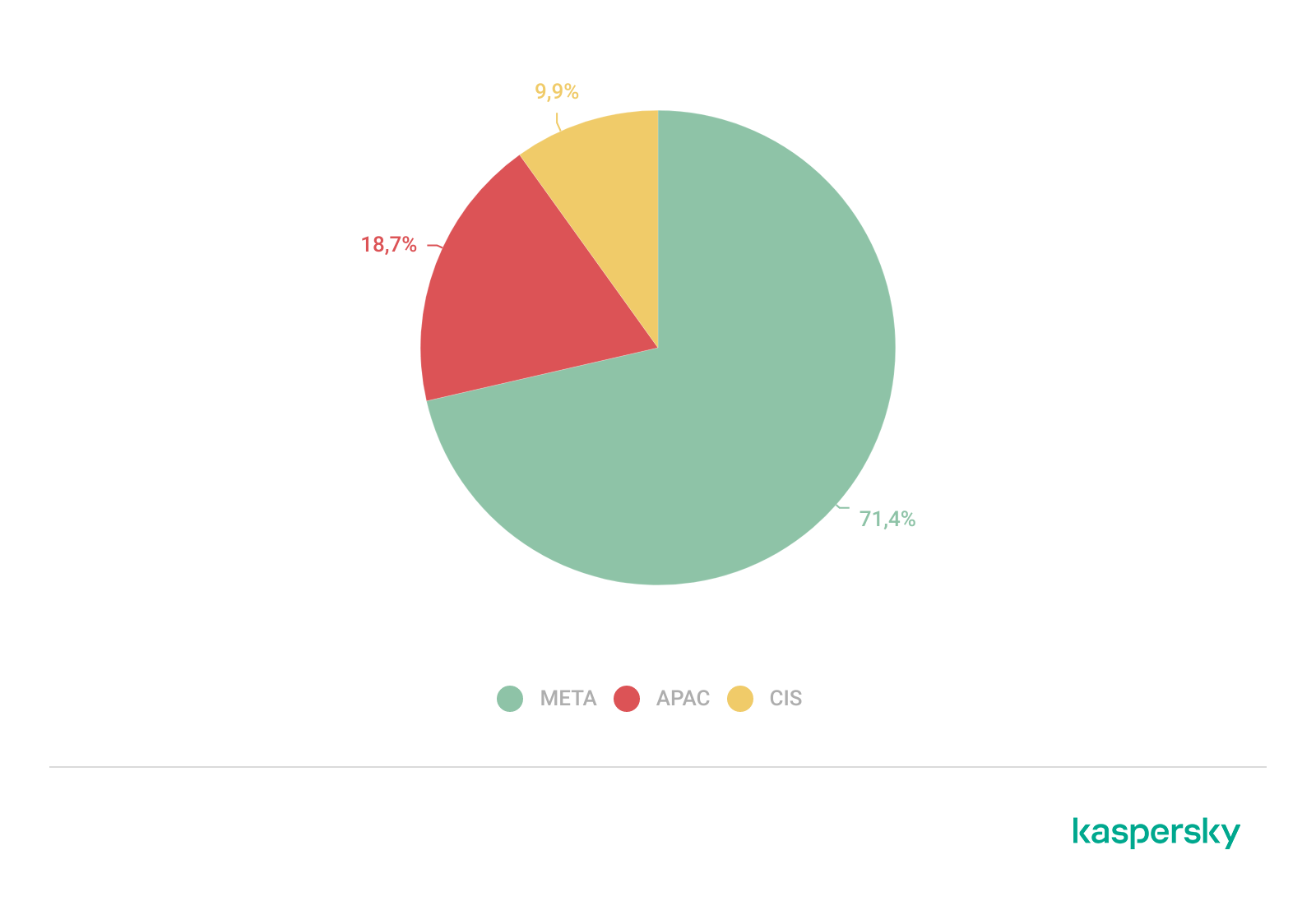
Географическое распределение инцидентов, выявленных в 2025 году в рамках проектов по поиску следов компрометации
К нам обращались организации из различных секторов экономики. На государственный сектор пришлось 29% инцидентов, далее следуют сфера образования (19%) и финансовый сектор (17%).
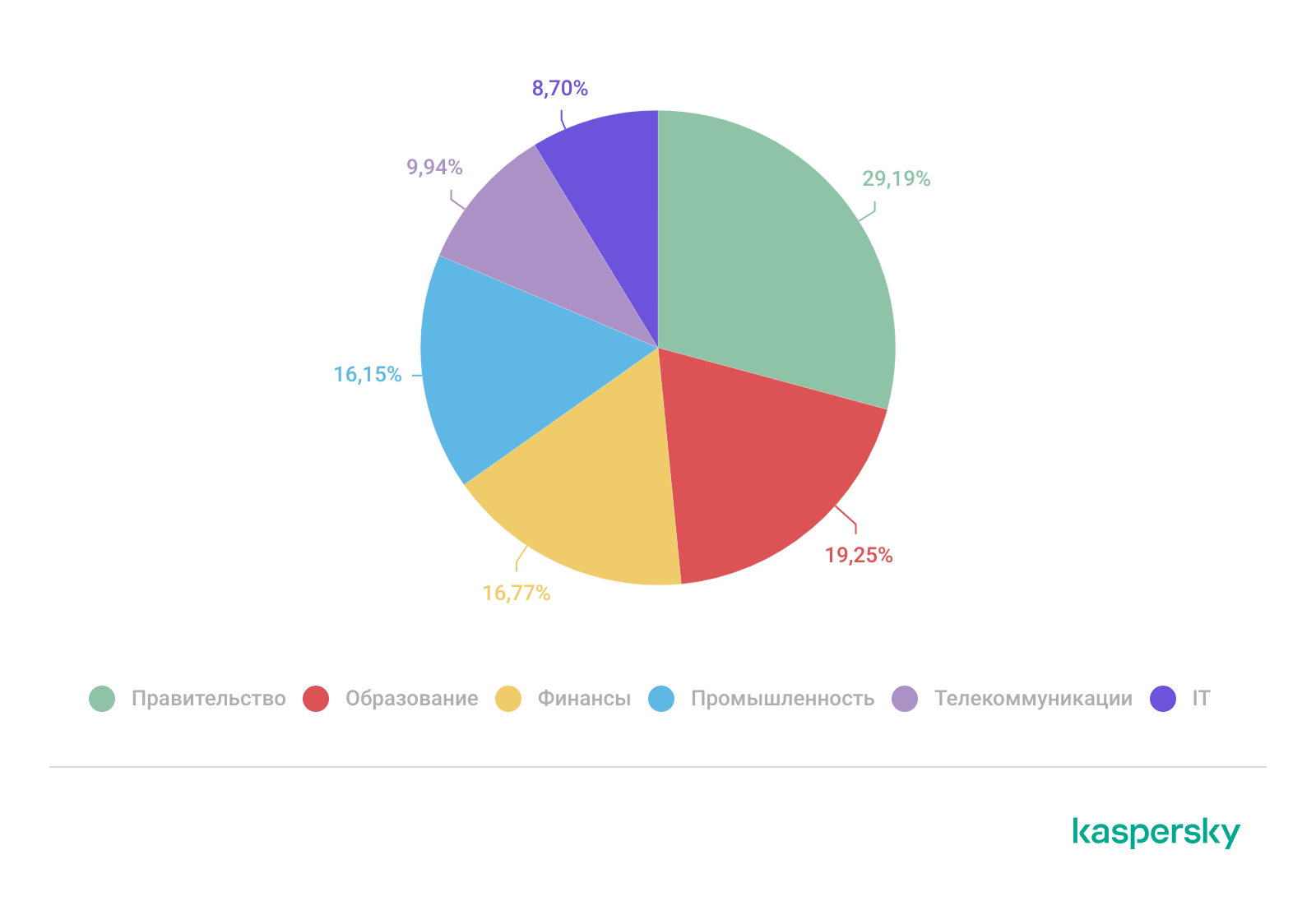
Распределение инцидентов, выявленных в 2025 году в рамках проектов по поиску следов компрометации, по секторам экономики
Категории признаков атак
Сервис Kaspersky Compromise Assessment опирается на постоянно обновляемый каталог индикаторов атаки (IoA). Поскольку полный список IoA слишком детализирован для обзорного отчета, мы сгруппировали их в ограниченный набор семейств детектирующих логик. По статистике, среди инцидентов доминируют три семейства:
- учетные данные из дампов — 12,4% всех инцидентов;
- конкретные LOLBin-утилиты — 11,2%;
- конкретные семейства вредоносного ПО — 11,2%.
Эти три семейства надежно и с высокой точностью указывают на компрометацию инфраструктуры — от «спящих» файловых угроз до многоэтапных атак с закреплением в системе.
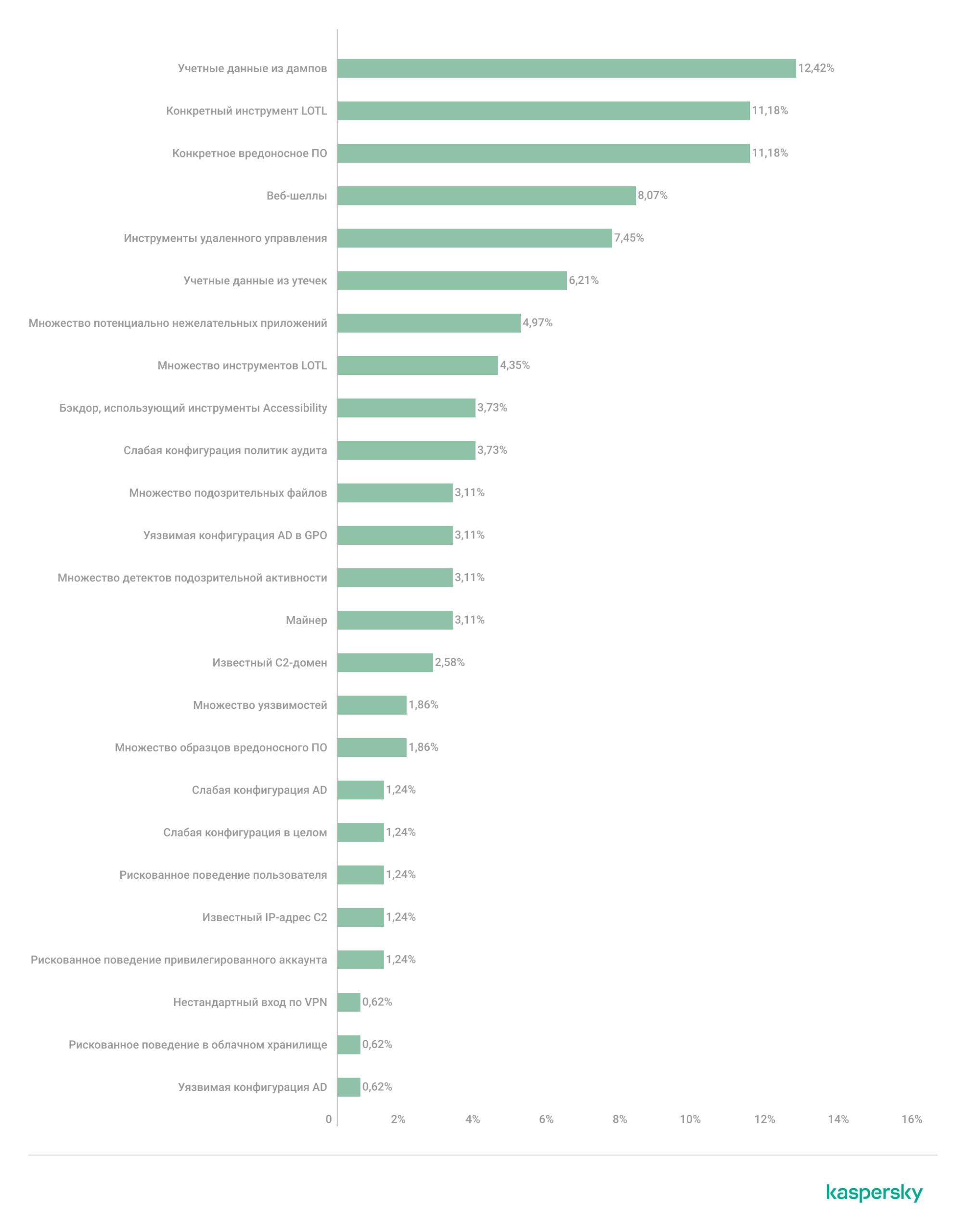
Распределение семейств детектирующих логик
Причины обращений в Kaspersky Compromise Assessment
Анализ проектов по поиску следов компрометации за 2025 год выявил четкую взаимосвязь между заявленными причинами обращения к нашим экспертам и профилем выявленных рисков. Чаще всего организации заказывают сервис в рамках проведения планового аудита (56%), далее следуют подготовка отчета для регуляторов (19%), аудит после инцидента безопасности (17%) и приобретение новой компании (9%).
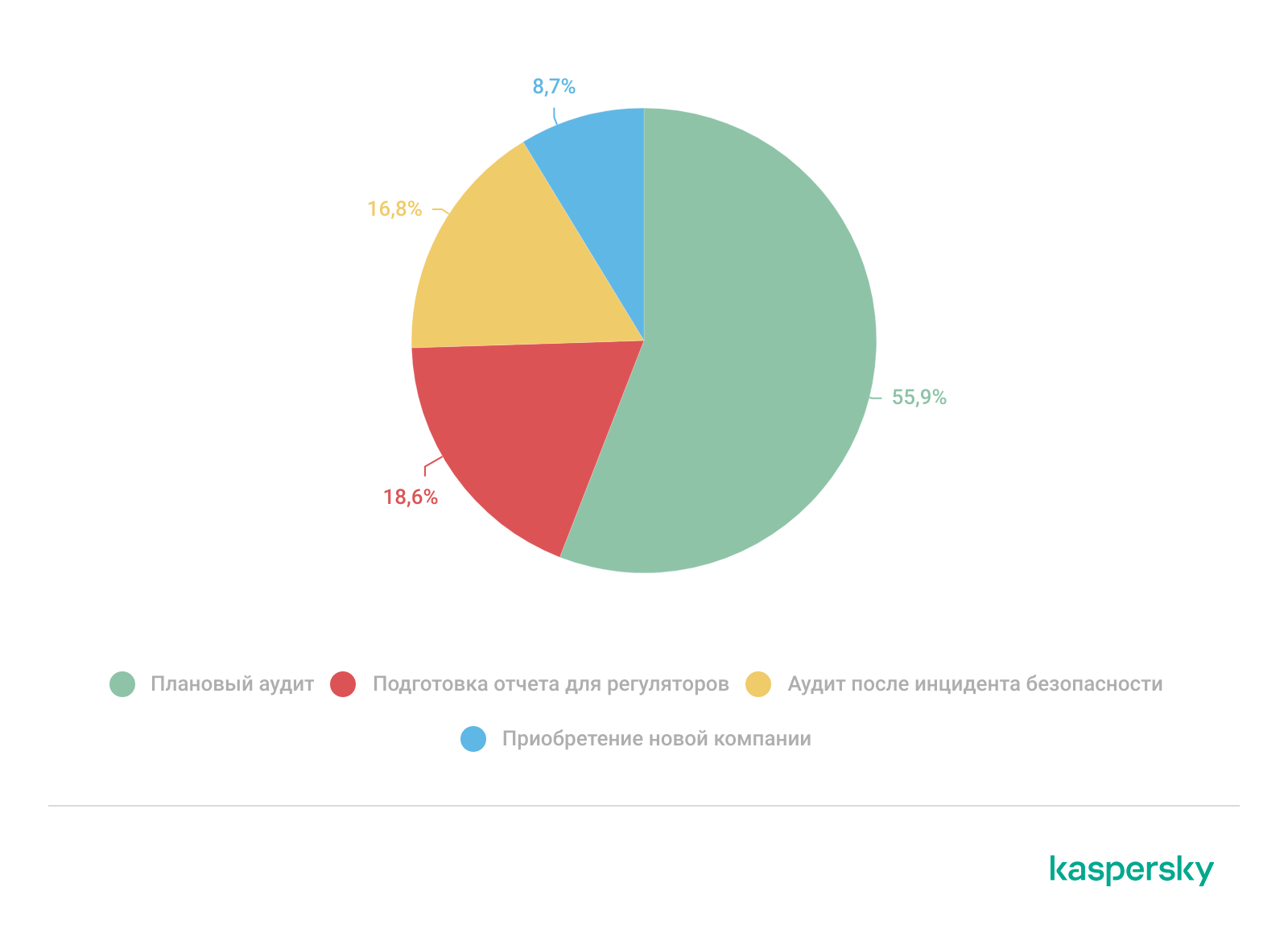
Статистика по причинам обращения в сервис поиска следов компрометации
Если сопоставить причины обращения с уровнем критичности обнаруженных инцидентов, то можно увидеть, что наибольшая доля инцидентов высокой степени критичности — 40,7% — приходится на организации, заказавшие поиск следов компрометации после инцидента. Более детальный анализ представлен ниже.
| Распределение инцидентов разной степени критичности в зависимости от причины обращения | ||||
| Критичность инцидента (%) | ||||
| Высокая | Средняя | Низкая | ||
| Причина обращения | Приобретение новой компании | 28,6 | 42,8 | 28,6 |
| Плановый аудит | 27,7 | 36,7 | 35,6 | |
| Подготовка отчета для регуляторов | 30 | 46,7 | 23,3 | |
| Аудит после инцидента безопасности | 40,7 | 25,9 | 33,4 | |
Компании, столкнувшиеся с инцидентами, часто обращаются к нам после того, как приняли первоначальные меры реагирования. Повышенная доля выявленных инцидентов высокой критичности указывает на то, что меры реагирования, которые, как правило, сосредоточены на локализации последствий известного инцидента, не дают полного представления о состоянии инфраструктуры. Как следствие, угрозы могут оставаться незамеченными после таких мероприятий до момента проведения полномасштабного поиска следов компрометации.
При слиянии и поглощении компаний к нам обращаются за оценкой сети присоединяемой организации на наличие скрытых угроз перед объединением двух сред. В таких случаях картина рисков выглядит сбалансированной: 28,6% находок относятся к инцидентам низкой критичности, 42,8% — к инцидентам средней критичности и 28,6% — к инцидентам высокой критичности. Это говорит о смешанном характере рисков в инфраструктурах поглощаемых компаний, которые обычно проверяются на наличие как известных уязвимостей, так и скрытой вредоносной активности. Другие категории превентивных обращений, такие как плановые аудиты и периодическая подготовка отчетности для регуляторов, демонстрируют схожее распределение, указывая на то, что регулярный поиск следов компрометации помогает выявлять серьезные проблемы на ранних этапах жизненного цикла атаки, снижая вероятность их развития до инцидентов высокой критичности.
Наибольшая доля инцидентов низкой критичности (36%) и наименьшая доля инцидентов высокой критичности (28%) наблюдались в организациях, регулярно проводивших аудиты. Со средней степенью уверенности можно заключить, что регулярные превентивный поиск следов компрометации позволяет эффективнее снижать вероятность возникновения критических инцидентов, чем реактивный поиск следов компрометации после произошедших инцидентов. Статистика за 2025 год подтверждает нашу гипотезу. Это значит, что интеграция в управленческие процессы регулярного поиска следов компрометации, выполняемого независимыми экспертами, может снизить вероятность неожиданных инцидентов высокой критичности и уменьшить общий уровень рисков.
В качестве иллюстрации различий между реактивным и превентивным подходами рассмотрим следующий пример из нашей практики, в котором устойчивая угроза находилась в сети заказчика в «спящем» состоянии и была обнаружена только в ходе комплексного поиска следов компрометации, проведенной после принятия первоначальных мер реагирования.
Пример из практики: «спящая» угроза, обнаруженная только в ходе поиска следов компрометации
Компания среднего размера столкнулась с инцидентом высокой критичности. Штатной команде реагирования удалось локализовать и устранить последствия угрозы в той мере, в которой о ней было известно из первоначального оповещения. После локализации инцидента организация решила убедиться, что в сети отсутствуют дополнительные очаги компрометации. Для этого были привлечены специалисты Kaspersky Compromise Assessment, которые провели полномасштабный криминалистический анализ инфраструктуры, выходящий за рамки первоначального инцидента.
Наши эксперты собрали криминалистические метаданные, логи событий безопасности и данные конфигурации Active Directory со всей инфраструктуры. Объединив полученную телеметрию, они провели поиск угроз в этих данных с помощью различных запросов, сконцентрированных на признаках закрепления, распространения в сети и аномальной активности процессов. В результате было выявлено и задокументировано несколько серьезных угроз, включая следующие механизмы закрепления в системе:
- Задача cron, запускающая веб-шелл
На критически важном веб-сервере Linux была обнаружена задача cron, которая автоматически загружала PHP-веб-шелл из публичного репозитория на GitHub и размещала его в директории, доступной из интернета. Даже в случае удаления файла специалистами по безопасности задача cron повторно загружала его из сети, обеспечивая злоумышленникам устойчивый механизм закрепления на веб-сервере и возможность удаленного выполнения кода.

- Активный реверс-шелл
На сервере, где размещалось веб-приложение, в списке процессов был обнаружен активный реверс-шелл, реализованный через bash.

Он был запущен от имени пользователя apache — той же учетной записи, под которой запускалось веб-приложение. Вероятно, атакующий воспользовался какой-то уязвимостью веб-приложения, чтобы получить возможность удаленного выполнения кода и наладить надежный канал управления, обходящий сетевой экран за счет того, что соединение инициировалось изнутри сети. - Стилер ClipBanker с закреплением через реестр Windows
На рабочей станции одного из пользователей была обнаружена разновидность стилера ClipBanker, закрепившаяся в системе через раздел реестра HKU\S-1-5-21-[СКРЫТО]-500\Software\Microsoft\Windows\CurrentVersion\Run\9Er6IIp.

Перед закреплением папка с вредоносным ПО была добавлена в исключения Защитника Windows, а к файлу были применены атрибуты «скрытый» и «системный», чтобы он не попался на глаза обычным пользователям.


- Вредоносный потребитель событий WMI с обманчивым псевдонимом
Также был обнаружен вредоносный потребитель событий WMI, который загружал и выполнял PowerShell-скрипт. Этот потребитель создает псевдоним kaspersky для команды Invoke-Expression, чтобы замаскировать свою активность под легитимную и снизить вероятность обнаружения при поверхностном анализе. Загружаемый скрипт (в настоящий момент недоступный), как подтвердили специалисты Kaspersky Threat Intelligence, представлял собой полезную нагрузку, отвечающую за дальнейшее распространение заражения.

Мероприятия по реагированию были сосредоточены на оперативной эффективной локализации конкретного инцидента, вызвавшего срабатывание оповещения. Однако более масштабный поиск следов компрометации выявила в среде множество бэкдоров, каждый из которых полагался на свою технику закрепления в системе — задачи cron, плановый запуск через реестр и WMI-подписки. Зараженные хосты не были охвачены в рамках первоначального реагирования, поэтому связанные с ними угрозы оставались незамеченными до проведения полномасштабного анализа.
Первоочередная задача специалистов по реагированию на инциденты — оперативно устранить явную угрозу, чтобы обеспечить непрерывность бизнес-процессов после выявленного инцидента. Поиск следов компрометации, в свою очередь, представляет собой комплексную проверку, позволяющую выявлять даже скрытые и неочевидные признаки заражения, где бы они ни находились. Когда своевременное реагирование дополняется регулярным поиском следов компрометации по всей сети, организация преуспевает не только в реактивной локализации инцидентов, но и в превентивном устранении скрытых признаков вредоносной активности. Проведенный анализ позволил выявить дополнительные плацдармы атакующих, повысить прозрачность инфраструктуры и снизить вероятность повторного инцидента.
Незамеченные давние инциденты
Многие инциденты остаются незамеченными в течение длительного времени, на что указывает статистика среднего времени обнаружения (MTTD) инцидентов в проектах по поиску следов компрометации. Например, в 2025 году мы обнаружили инцидент, возраст которого составлял около четырех лет.
В 30,8% случаев следы компрометации охватывали период более трех месяцев. Такое длительное время обнаружения может обернуться серьезными последствиями для организации. При этом инциденты могут иметь различную природу: от «спящих» файловых угроз до устойчивых компрометаций, что подчеркивает необходимость надежных механизмов обнаружения и реагирования.
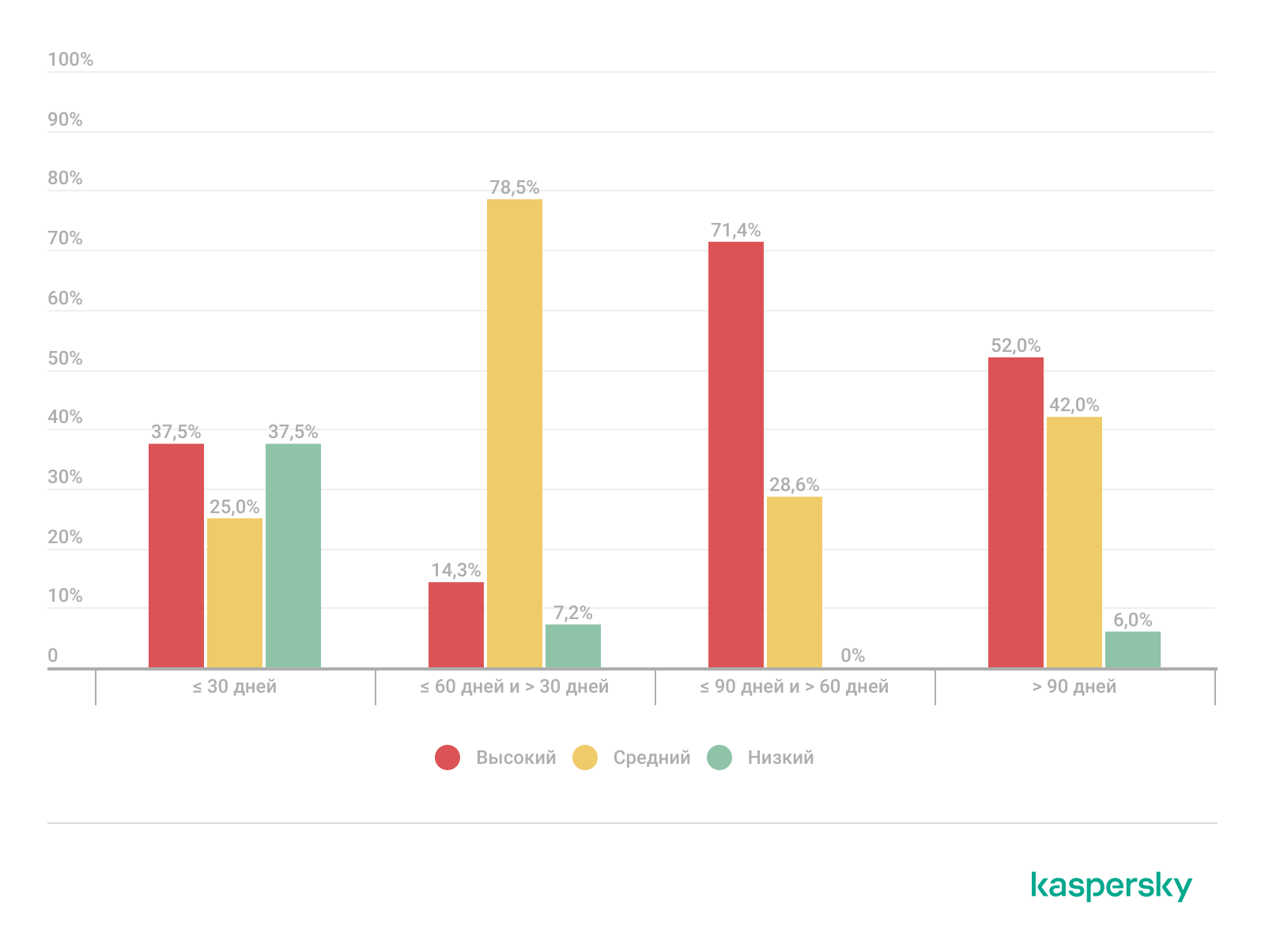
Распределение инцидентов по критичности в зависимости от MTTD
Для анализа взаимосвязи между задержкой обнаружения и критичностью инцидентов мы сгруппировали результаты с учетом MTTD.
- Для инцидентов, обнаруженных в течение первого месяца, уровень критичности распределяется относительно равномерно между низкой, средней и высокой категориями.
- По мере увеличения MTTD наблюдается смещение в сторону более высокой критичности. Примечательно, что подавляющее большинство инцидентов, обнаруженных через 30–60 дней после компрометации, относится к категории средней критичности (78,57%), тогда как инциденты с временем обнаружения от 60 до 90 дней преимущественно являются высококритичными (71,43%).
- Среди инцидентов, выявленных спустя более 90 дней, значительную долю также составляют высококритичные случаи (52%).
В целом 52% всех высококритичных инцидентов обнаруживаются только спустя 90 дней их незамеченного присутствия. Риск очевиден: промедление с обнаружением повышает вероятность более серьезной компрометации. Организации, внедряющие непрерывное обнаружение, практики активного поиска угроз и регулярный поиск следов компрометации, могут сократить MTTD, ограничить эскалацию атак и снизить общий уровень рисков.
Следующий пример из нашей практики подчеркивает, насколько своевременное обнаружение и реагирование важны для того, чтобы инцидент не перешел в категорию высокой критичности.
Пример из практики: четыре года скрытого майнинга криптовалюты на контроллерах домена
В мае 2025 года эксперты по поиску следов компрометации обнаружили, что три контроллера домена в сети заказчика были заражены вредоносными файлами, которые оставались незамеченными на протяжении почти четырех лет. Вредоносные файлы были спрятаны в папке C:\Windows\Fonts\Mysql, в которой обычным пользователям видны только файлы шрифтов. В ней были обнаружены файлы с именами nei.bat, dl1host.exe, bat.bat и cmd.bat, а также поддельный svchost.exe, созданные в июне и июле 2021 года.
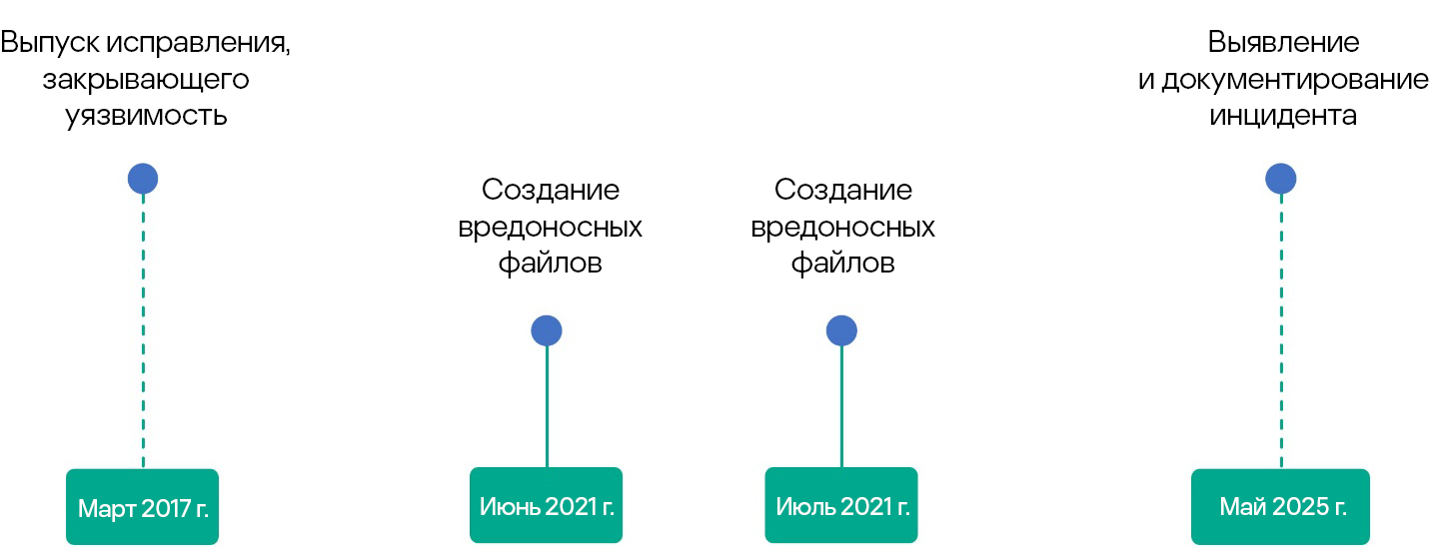
Согласно данным Kaspersky Threat Intelligence, указанные файлы связаны с кампанией скрытого майнинга криптовалюты под названием NSABuffMiner. Соответствующее вредоносное ПО распространяется через протокол SMB с использованием уязвимости EternalBlue (MS17-010). Исправление к ней было выпущено за четыре года до первоначальной компрометации (в марте 2017 года), то есть времени для обновления систем было более чем достаточно. Этот случай подчеркивает важность правильно выстроенных процессов управления обновлениями и мониторинга потоков данных об угрозах.
По запросу заказчика вредоносные файлы были собраны вместе с образом системы для дальнейшего криминалистического анализа, который выявил следующее:
- Файлы bat.bat и cmd.bat генерируют случайные IP-адреса и сканируют их с помощью облегченного порт-сканера, переименованного в taskhost.exe, для выявления активных и уязвимых хостов с открытым SMB-портом 445 и NetBIOS-портом 139.
- Обнаруженные уязвимые IP-адреса передаются вспомогательным скриптам poad.bat, poab.bat, load.bat и loab.bat, запускающим вредоносные компоненты mance.exe, Eter.exe и puls.exe. Эти компоненты внедряют вредоносные DLL-библиотеки Eternalblue2.dll и Doublepulsar2.dll в процессы lsass.exe и explorer.exe для реализации механизма дальнейшего распространения.
- Далее для закрепления в системе создаются задачи планировщика, выполняющие скрипты распространения и заражения, а также создаются службы, запускающие криптомайнер. Эти задачи и службы называются MicrosoftMysql, MicrosoftFonts и MicrosoftMSSql. В планировщике также встречались задания под именами At1 и At2, созданные с аналогичной целью.
- После успешной компрометации и установки механизмов закрепления выполняется процедура очистки: с диска удаляются временные файлы и файлы вредоносных компонентов.
Из-за отсутствия надлежащих процедур мониторинга и поиска угроз организация не знала, что в течение четырех лет злоумышленники майнили криптовалюту на их контроллерах домена.
Ненамеренное сохранение вредоносных компонентов
При поиске следов компрометации мы часто сталкиваемся с ситуациями, когда веб-шеллы остаются в системах либо восстанавливаются в целевой инфраструктуре. Согласно данным обращений в сервис Compromise Assessment за 2025 год, 64% инцидентов с веб-шеллами были отнесены к категории высокой критичности, 7% — к категории низкой критичности (в этом случае существует вероятность компрометации, но найденные файлы могут быть и легитимными) и 29% — к категории средней критичности (в этом случае файлы необходимо удалить).
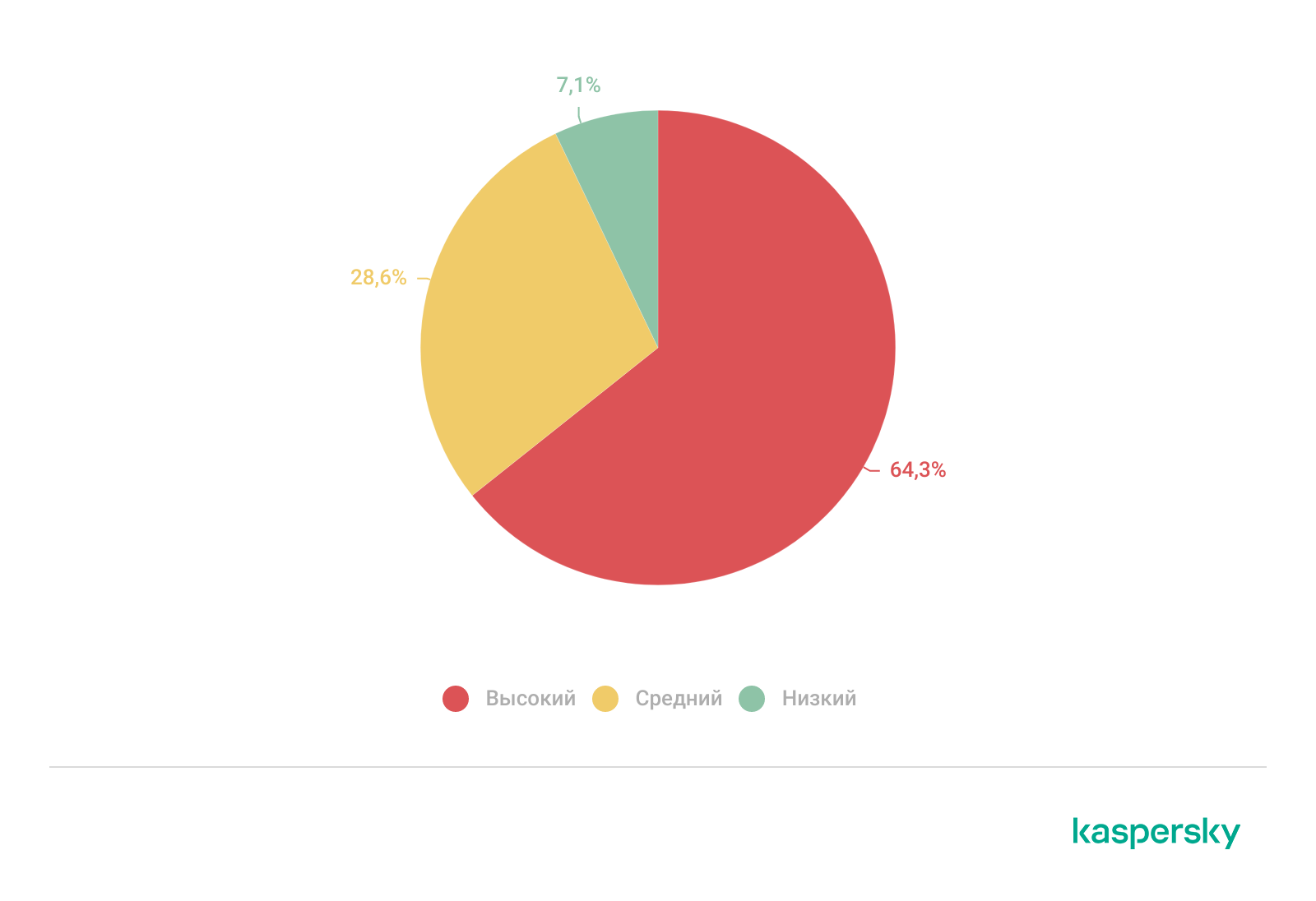
Распределение инцидентов с веб-шеллами по уровню критичности
Один из способов закрепления веб-шеллов в системе — заражение резервных копий. Согласно статистике выявленных в ходе наших проектов инцидентов, 60% веб-шеллов было обнаружено в активных системах, а 40% — в резервных копиях. Восстановление таких копий может приводить к повторной компрометации спустя длительное время после первоначального заражения.
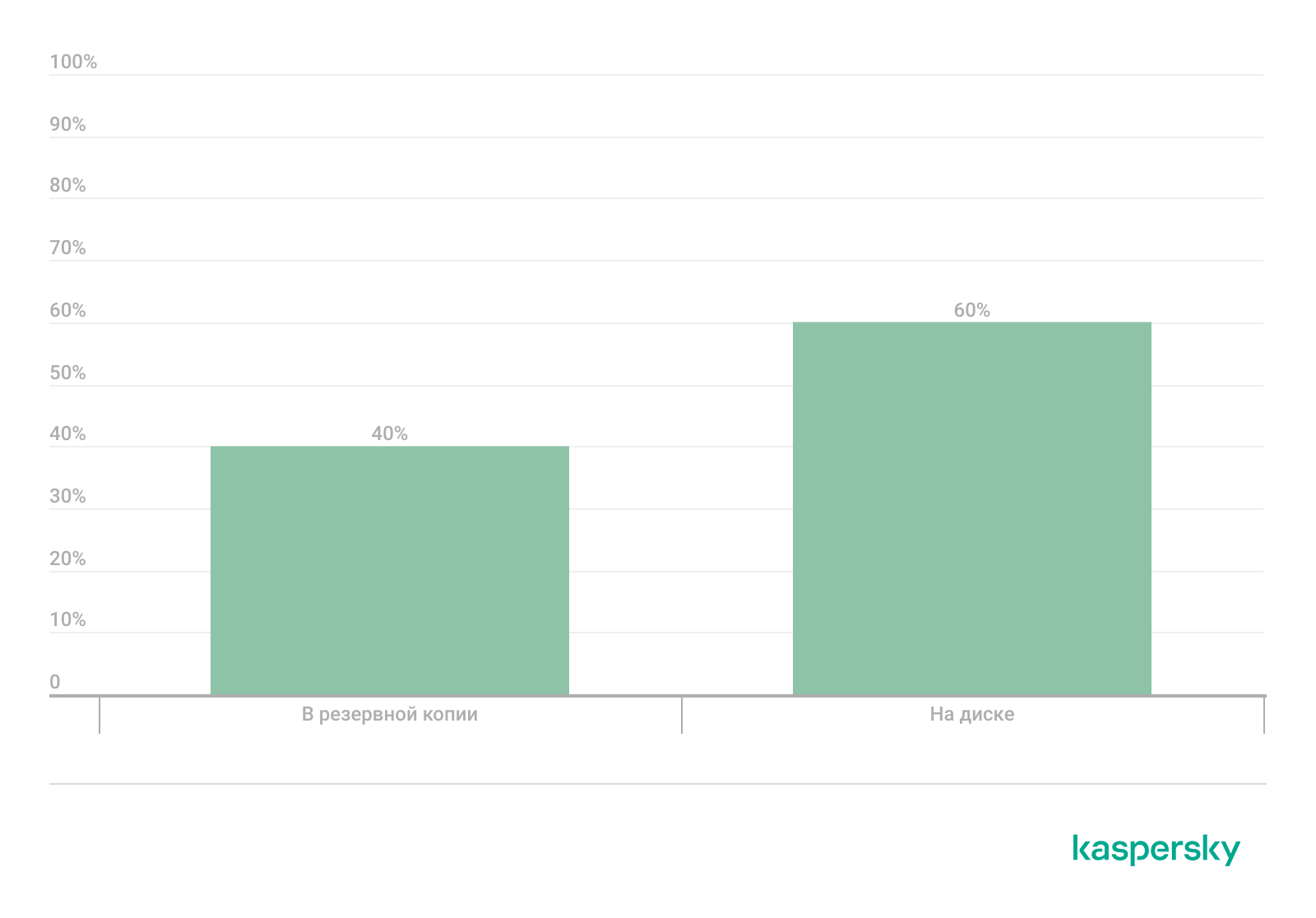
Расположение веб-шеллов
Еще одна распространенная проблема — недочеты в инвентаризации активов, наблюдавшиеся в 25% случаев. Речь идет о неучтенных системах, в том числе облачных Linux-серверах, не подключенных к Active Directory, которые не видны стандартным механизмам сканирования.
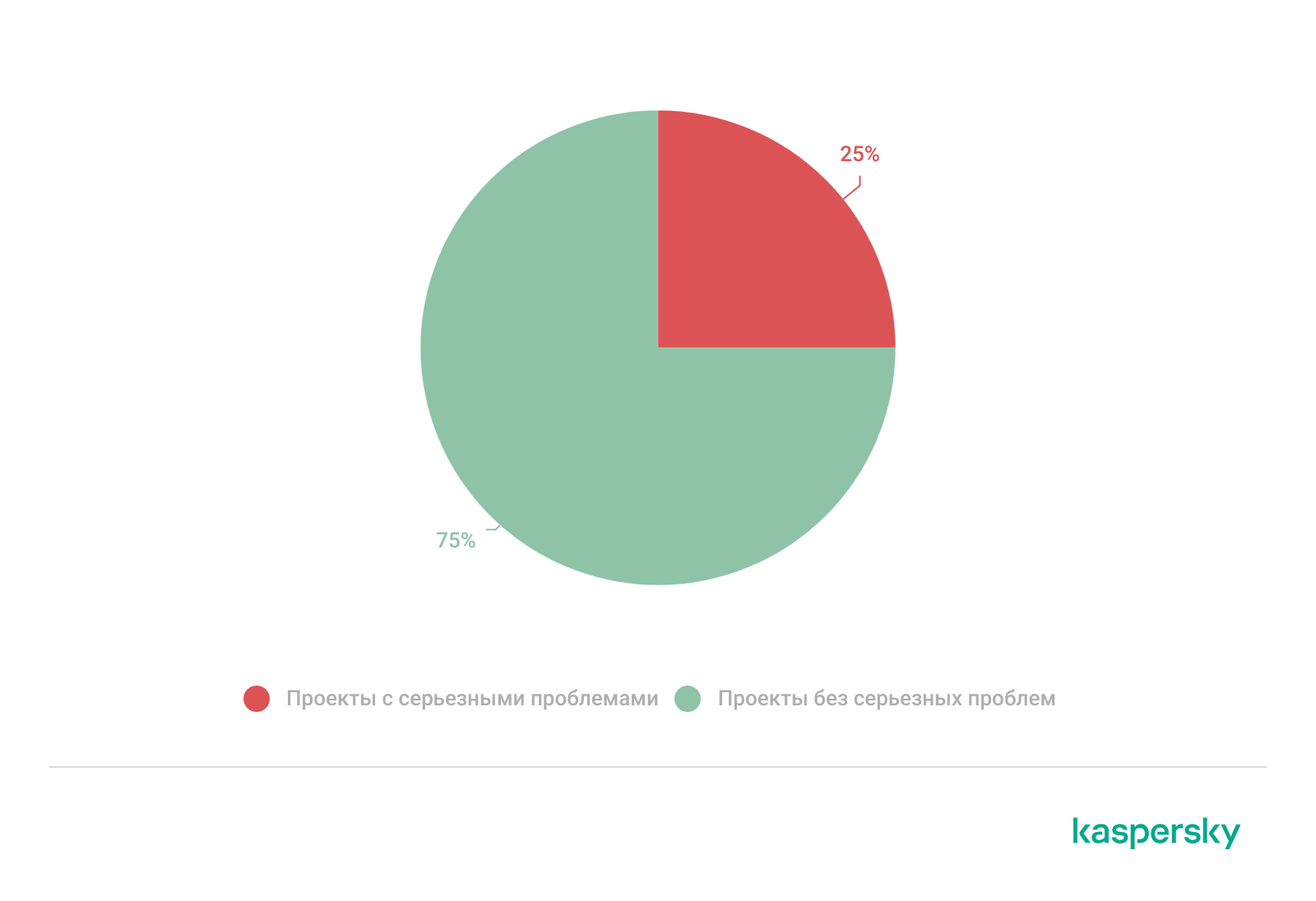
Проблемы с инвентаризацией активов
Злоумышленники могут внедрять веб-шеллы на облачные серверы, которые не отражаются в инвентарных списках, но при этом с них регулярно делаются резервные копии. В результате веб-шелл может длительное время оставаться на таком сервере, и даже если он будет в какой-то момент удален, сервер резервного копирования позднее восстановит зараженные файлы, после чего веб-шелл снова будет доступен извне. Это подчеркивает, что без полного и актуального перечня активов возможности обнаружения и реагирования существенно ограничены.
В одном из случаев веб-шелл был скрыт на внутреннем файловом сервере (не веб-сервере) внутри RAR-архива по следующему пути: D:\backup\[СКРЫТО].rar/wwwroot/<…>/[СКРЫТО].aspx.
В ходе расследования администраторы сервера сообщили, что папка была скопирована с веб-сервера, который был выключен на момент проведения поиска следов компрометации. Из-за неполной инвентаризации активов штатная команда безопасности не обнаружила компрометацию веб-сервера, а после выполнения процедур резервного копирования веб-шелл оказался на внутреннем файловом сервере. Криминалистический анализ выключенного веб-сервера показал, что злоумышленникам удалось внедрить бэкдор на большинстве Windows-серверов в инфраструктуре, настроив на них учетные записи локального администратора с одинаковым паролем.
В ходе атаки злоумышленники выполнили через PsExec на всех серверах, перечисленных в TXT-файле, CMD-скрипт, который изменял пароль учетной записи локального администратора на указанное в скрипте значение:

Легитимные, но подозрительные: инструменты удаленного управления и LoLBin-утилиты
В 2025 году во всех проектах по поиску следов компрометации мы сталкивались с использованием нестандартных средств удаленного управления. Также в каждом проекте присутствовали легитимные исполняемые файлы, которые можно использовать во вредоносных целях (living-off-the-land binaries, LoLBins). Наличие и тех и других усложняет задачу детектирования для центров мониторинга и реагирования (SOC), которым необходимо различать легитимное администрирование и вредоносную активность.
Среди инструментов удаленного управления встречались различные проприетарные платформы, такие как TeamViewer и AnyDesk, а также свободно распространяемые решения, включая PsExec, VNC-серверы и фреймворки с открытым исходным кодом. Во многих средах подобные исполняемые файлы применяются повседневно при устранении проблем, развертывании ПО и оказании удаленной поддержки. Однако такие же действия — создание новых локальных административных учетных записей, копирование файлов на удаленные ресурсы, запуск сканирования сетевых портов —совершают и злоумышленники после компрометации. Наши аналитики часто сталкиваются с ситуациями, когда легитимные действия системных администраторов неотличимы от попыток горизонтального перемещения в инфраструктуре, поэтому одного лишь факта использования инструмента удаленного доступа недостаточно, чтобы связать эту активность с инцидентом. В таких случаях поведение должно оцениваться относительно базового профиля применения инструмента в конкретной организации. Формирование такого профиля требует глубокого контекстного понимания того, кому разрешено использовать инструмент, с каких конечных устройств и при каких условиях. Это трудоемкий процесс, требующий индивидуального подхода.
LoLBin-утилиты, встроенные в операционную систему или часто устанавливаемые пользователями, такие как certutil, bitsadmin, regsvr32 и wmic, также регулярно встречались в инцидентах во всех проектах. Хотя это доверенные системные компоненты, согласно нашим аналитическим данным об угрозах, они нередко используются злоумышленниками для дальнейшего распространения, эксфильтрации данных и закрепления в системе. Распределение по критичности инцидентов, в которых были задействованы нежелательные программы (riskware) или LoLBin-утилиты, представлено на графике ниже. Относительно высокая доля инцидентов средней (40%) и высокой (31%) критичности подчеркивает, что использование легитимных утилит часто становится ключевым вектором, позволяющим злоумышленникам развить атаку за пределы первоначального плацдарма.
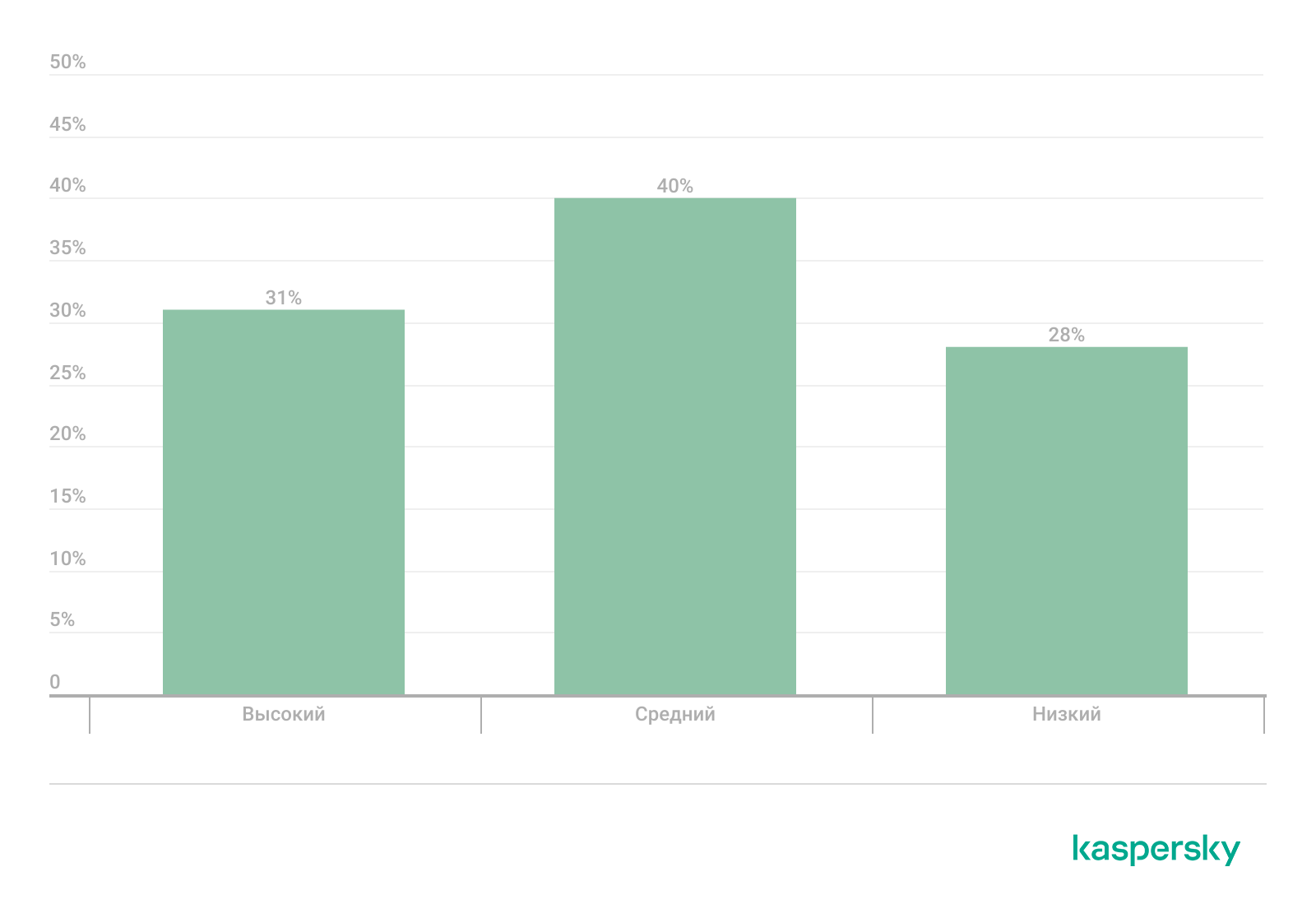
Распределение инцидентов, в которых применялось нежелательное или легитимное ПО, по критичности в 2025 году
Чтобы выявлять потенциальное использование злоумышленниками LoLBin-утилит и инструментов удаленного управления, мы рекомендуем применять многоуровневый подход, который значительно эффективнее статических списков запрещенных приложений:
- Разработайте политику, в которой перечислены разрешенные к использованию инструменты удаленного управления. Ее стоит применять совместно с требованием обязательно передавать логи работы таких программ в централизованную систему управления событиями безопасности (SIEM или специальный агрегатор логов). Постоянный мониторинг этих данных позволяет SOC выявлять отклонения от стандартных профилей разрешенного использования.
- Регулярно проводите инвентаризацию программного обеспечения для выявления неутвержденных инструментов удаленного управления. По возможности собирайте данные из следующих разделов реестра на всех хостах:
- HKLM\Software\Microsoft\Windows\CurrentVersion\Uninstall
- HKLM\Software\WOW6432Node\Microsoft\Windows\CurrentVersion\Uninstall
- HKEY_USERS\*\Software\Microsoft\Windows\CurrentVersion\Uninstall
- HKEY_USERS\*\Software\Wow6432Node\Microsoft\Windows\CurrentVersion\Uninstall
- Обогощайте хэши (MD5/SHA-256) каждого запускаемого исполняемого файла функциональной категорией, например «Удаленный доступ», «Эталонный образ» или «Защитное ПО». Сопоставление категорий с путем запуска позволяет выявлять случаи, когда исполняемый файл запускается из нетипичного расположения, например программа категории «Удаленный доступ» — из %TEMP% или папки загрузок пользователя.
- Внедрите правила детектирования, основанные на известных шаблонах злоупотребления LoLBin-утилитами, таких как certutil -decode, bitsadmin -transfer, regsvr32 -i <dll> и wmic process call create. Эти правила должны всегда сопоставляться с базовым профилем, который описывает нормальную активность утилиты в организации и формируется на основе периода подтвержденной легитимной работы. Когда появляются новые легитимные сценарии использования, базовый профиль должен обновляться. Оповещения следует генерировать только при отклонении наблюдаемого поведения от установленной нормы — так снижается уровень шума в оповещениях, но сохраняется чувствительность к реальным угрозам.
Отсутствие постоянного мониторинга и превентивного поиска угроз
Анализ недавних проектов по поиску следов компрометации выявил систематическую слепую зону в организациях, выстроивших систему защиты по принципу «купил и забыл». Когда отсутствует постоянный мониторинг специалистами или отдельная программа поиска угроз, уровень критичности обнаруживаемых инцидентов сильно смещается в сторону более высокого:
| Распределение инцидентов по степени критичности при отсутствии круглосуточного мониторинга или активного поиска угроз | ||
| Особенности системы безопасности | Низкая критичность | Средняя/высокая критичность |
| Без постоянного мониторинга | 14% | 86% |
| Без активного поиска угроз | 16% | 84% |
Зачастую проблема заключается не в отсутствии инструментов, а в неэффективном их использовании. Многие организации внедряют современные решения безопасности, но эксплуатируют их в режиме «настроил и забыл» либо выстраивают процессы исключительно вокруг реагирования на оповещения. Для таких организаций характерны следующие проблемы:
- Усталость от оповещений — высокая доля ложноположительных срабатываний снижает внимательность аналитиков, вынуждая их сортировать события по поверхностным признакам вместо проведения глубокого контекстного расследования.
- Фрагментированное распределение задач между аналитиками — при отсутствии выделенной команды по поиску угроз одному аналитику могут поступать десятки несвязанных оповещений, что ограничивает время, которое он может посвятить выдвижению и проверке гипотез, которые необходимы для выявления скрытых точек доступа злоумышленников.
На практике это приводит к тому, что злоумышленники дольше остаются в системе и могут перемещаться по сети и выгружать данные, пока организация не заметит взлом. Речь идет об измеримом риске, который напрямую влечет негативные последствия для бизнеса. Следующий пример показывает, что внедрение защитного решения само по себе не гарантирует обнаружение угроз, и подчеркивает важность непрерывного мониторинга, регулярной валидации оповещений и структурированного поиска угроз для сокращения времени присутствия злоумышленников в сети и минимизации последствий для бизнеса.
Пример из практики: «защищенная на уровне архитектуры» среда без постоянного мониторинга
Компания приобрела решения безопасности и после внедрения исходила из того, что их среда теперь «защищена на уровне архитектуры» (secure by design). Однако эффективны только те средства защиты, которые корректно настроены, постоянно адаптируются в процессе эксплуатации и подкреплены активным мониторингом. Решения были развернуты, но за их настройками не следили, аналитики не проверяли генерируемые оповещения, не было процедуры отсмотра просмотра собранных логов по расписанию.
Когда организация приняла решение воспользоваться сервисом Compromise Assessment, эксперты «Лаборатории Касперского» собрали и проанализировали логи событий безопасности. Цель была проста — определить, что на самом деле происходило в сети за последние месяцы.
В логах были обнаружены однозначные признаки вредоносной активности. В частности, были выявлены следы использования Impacket для развертывания Cobalt Strike и применения Mimikatz на ряде критически важных серверов, включая контроллеры домена. Все эти действия произошли за три месяца до обнаружения, и компания не знала о них из-за отсутствия эффективного круглосуточного мониторинга.
Impacket представляет собой набор Python-скриптов для работы с сетевыми протоколами и низкоуровневого взаимодействия с сетевыми пакетами, который может использоваться злоумышленниками для дальнейшего распространения в сети. Ниже приведен пример артефактов Impacket, которые были обнаружены в сети:

С помощью Impacket злоумышленники выполнили команду PowerShell, которая загрузила исполняемый файл с удаленного командного сервера. Было установлено, что данный сервер связан с инфраструктурой Cobalt Strike. Cobalt Strike используется злоумышленниками на этапе после компрометации и предоставляет возможности удаленного выполнения команд и перемещения внутри скомпрометированной сети. Запуск этого инструмента был организован через задачу планировщика, замаскированную под легитимное обновление Google Chrome.


Анализ хронологии событий также подтвердил наличие в скомпрометированной системе бинарного файла Mimikatz и дампа памяти, связанных с тем же инцидентом, что подтверждает кражу учетных данных.

Организация не подозревала о взломе: вредоносная активность оставалась незамеченной в течение трех месяцев, поскольку никто не отвечал за мониторинг внедренных средств защиты. Узнав о результатах проверки, организация инициировала полномасштабные мероприятия по реагированию на инцидент, чтобы ликвидировать очаги присутствия злоумышленников, провести ротацию учетных данных и повысить защищенность инфраструктуры.
Средства безопасности не самодостаточны: установка сетевого экрана или EDR-решения не обеспечивает автоматической защиты. Без корректной настройки, формирования и поддержания базового профиля активности, а также, что особенно важно, непрерывного мониторинга логов и активного поиска угроз такие средства могут работать впустую. Наличие непрерывного мониторинга собственными силами или с привлечением сторонних специалистов, включающего корреляцию событий, выявление аномального использования платформ тестирования на проникновение и хакерских утилит, а также расследование другой подозрительной активности, может стать решающим фактором, определяющим, перерастет ли инцидент в длительную компрометацию или будет обнаружен за несколько минут.
Статистика реагирования на инциденты
Как показывает анализ прошлых проектов по поиску следов компрометации, между сценариями реагирования на инциденты, основанными на рекомендуемых отраслевых методиках, и их фактической реализацией в неподготовленных средах часто существует разрыв, особенно при наличии устаревших систем. На диаграмме ниже показана частота выполнения различных действий на начальном этапе реагирования на инциденты по результатам поиска следов компрометации.
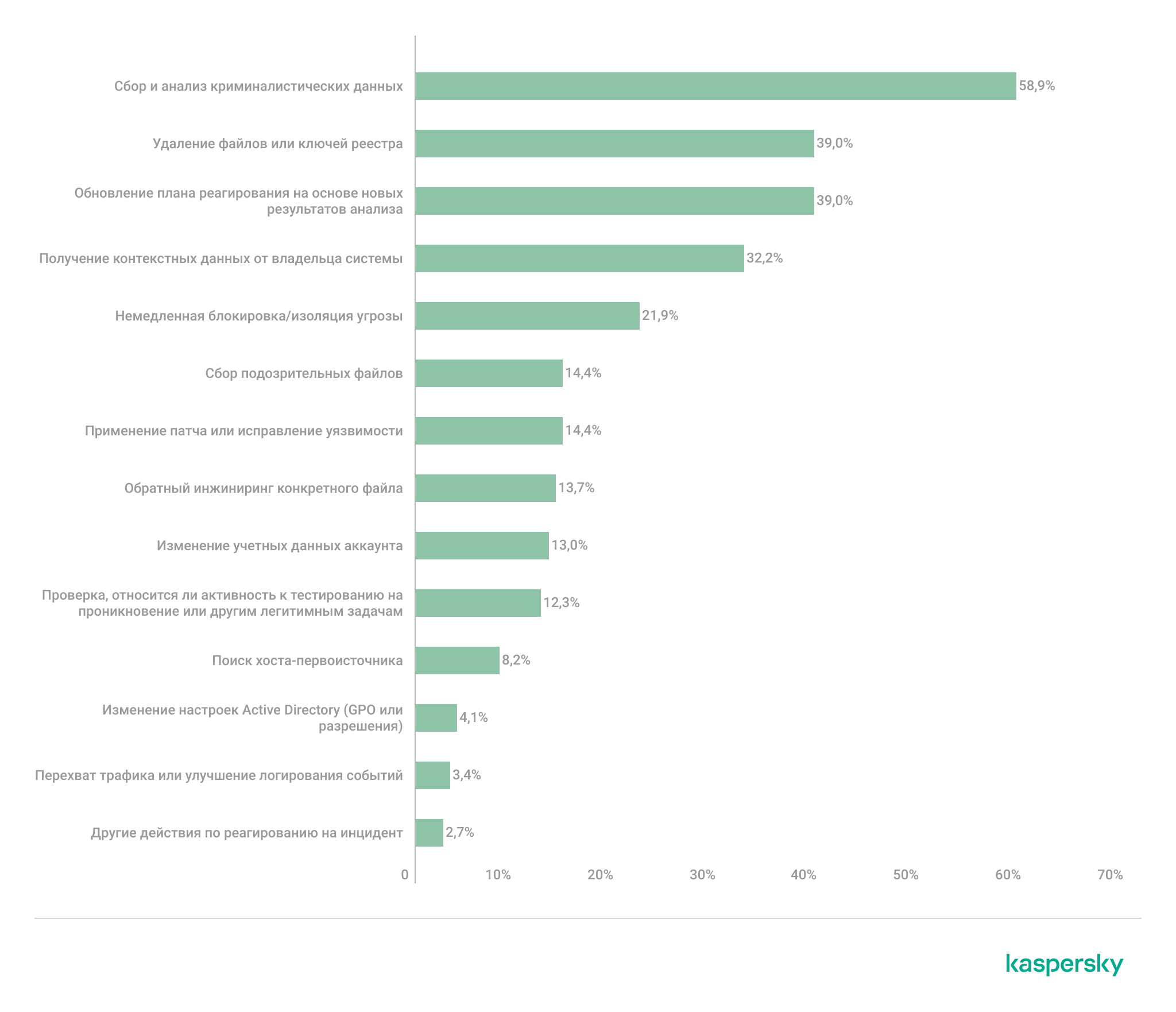
Меры реагирования, принимаемые при обнаружении инцидентов в ходе поиска следов компрометации
В этом распределении четко выделяются три наиболее распространенных действия:
- Криминалистический анализ проводился в большинстве инцидентов: примерно в 59% случаев требовались сбор и анализ как минимум одного набора криминалистических данных.
- Дистанционное удаление вредоносного ПО (например, файлов или разделов реестра) выполнялось в 39% случаев.
- План реагирования пересматривался в ходе расследования в 39% проектов, что отражает итеративный характер процесса.
Почему реагирование чаще всего начинается со сбора криминалистических данных
Сбор и анализ пакетов криминалистических данных стал наиболее распространенным этапом реагирования, который потребовался в 59% случаев. Это объясняется двумя факторами, характерными для проектов по поиску следов компрометации: 1) ограниченной доступностью исторических событий в исследуемых организациях и 2) тем, что значительная часть инцидентов произошла более чем за 90 дней до начала поиска следов компрометации. Во многих случаях стандартные логи событий были перезаписаны или утрачены, что вынуждало исследователей восстанавливать хронологию событий по остаточным артефактам, таким как записи MFT, кусты реестра и временные метки файловой системы.
Согласно нашим наблюдениям, удаленный сбор пакетов криминалистических данных является первоочередной задачей, а не просто удобной возможностью. На графике ниже представлены сводная информация о способности организации удаленно собрать пакет криминалистических данных в зависимости от уровня критичности инцидентов. Они показывают, что в значительной части высококритичных случаев у организаций отсутствовала такая возможность.
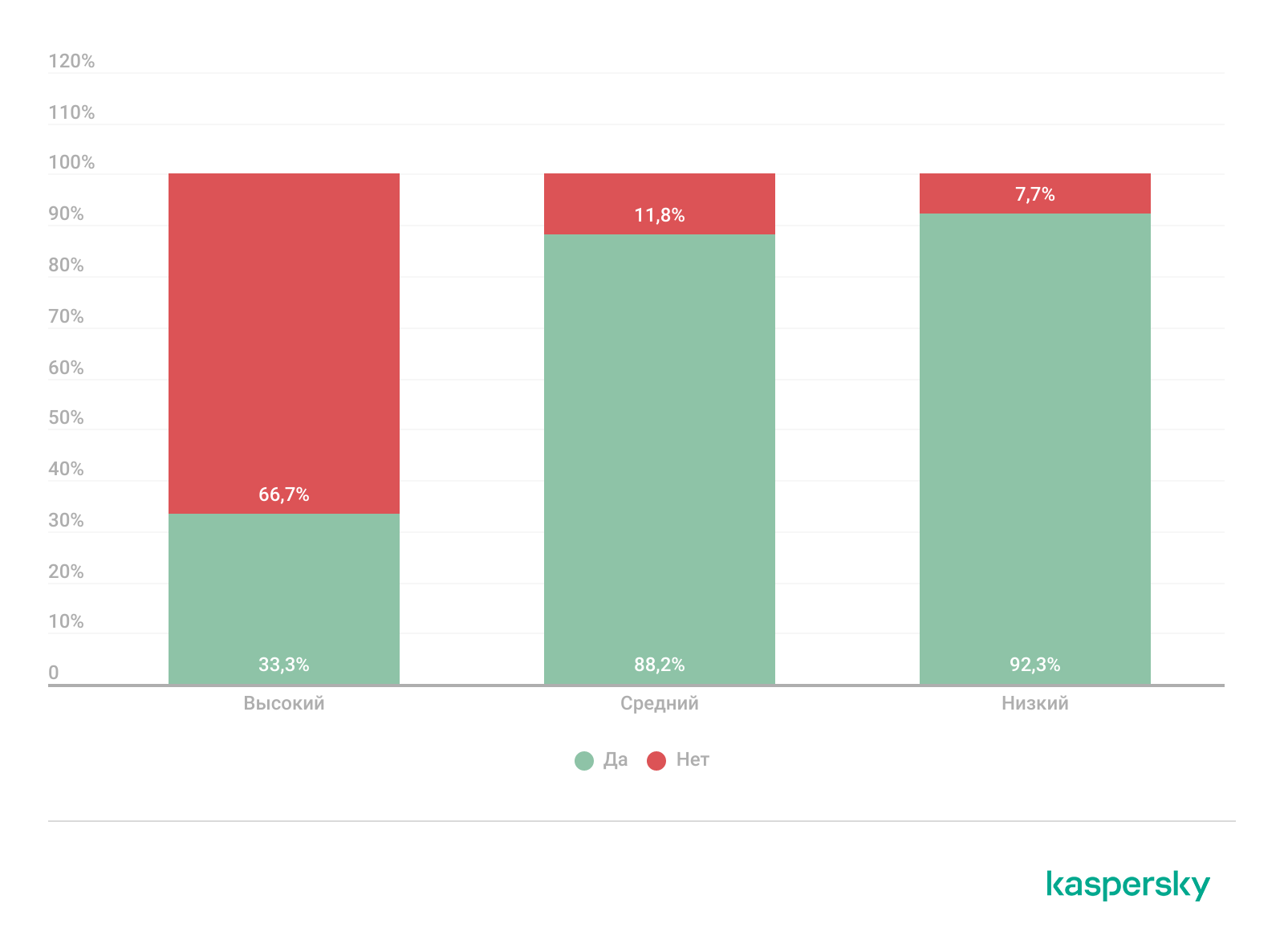
Способность удаленно собирать криминалистические данных в организациях с разбиением по критичности инцидентов
Сдерживание угрозы: проблемы корректного удаления файлов и записей реестра
Принятие мер по нейтрализации угрозы — например, удаление файлов или разделов реестра (потребовалось в 39% случаев) — еще один важный этап реагирования на инциденты, однако практическая его реализация в организациях нередко оставляла желать лучшего. Хотя многие клиенты и заявляли о возможности дистанционного удаления через решения EDR, на практике такие операции нередко передавались IT-командам или MSP-провайдерам через системы заявок, что могло приводить к задержкам и снижению качества результата. Удаление вредоносного программного обеспечения требует хирургической точности, особенно в многоэтапных и бесфайловых сценариях или при глубоком закреплении в системе. Чтобы ликвидация была полной и своевременной, технические возможности должны сочетаться с экспертными знаниями, четким планированием и тщательным выполнением плана. Это особенно важно с учетом того, что артефакты могут быть спрятаны в теневых и резервных копиях, скрытых каталогах или цепочках загрузчиков.
Коммуникационные проблемы как дополнительная операционная сложность
Любопытное наблюдение оказалось связано с коммуникацией. В 32% проектов на процесс реагирования существенно влияли коммуникационные проблемы внутри организаций. Типичные примеры:
- Неоднозначное подтверждение действий — системные администраторы не могли оперативно определить, является ли подозрительный файл легитимным.
- Задержки валидации со стороны владельцев систем — обработка инцидентов замедлялась в ожидании ответа от владельцев систем.
- Скомпрометированные каналы связи — при подозрениях на компрометацию домена можно предполагать, что учетные записи электронной почты или порталы поддержки также уже под контролем злоумышленников.
- Текучесть кадров — утрата знаний о предыдущих базовых конфигурациях.
Все это подчеркивает необходимость регулярных тренингов в формате ролевой игры, позволяющих отрабатывать не только техническую часть сценариев реагирования, но и взаимодействие между участниками процесса, а также проверять соблюдение соглашений об уровне операционной поддержки (OLA), регламентирующих взаимодействие между командами, и стандартных операционных процедур (SOP), используемых для корректного документирования.
Итеративное обновление плана реагирования
В 39% случаев возникала необходимость скорректировать планы реагирования с учетом новых аналитических данных. Этим наблюдением подтверждается постулат о том, что реагирование на инциденты по своей природе является итеративным процессом. Планы, составленные на начальных этапах, объективно не могут учитывать все потенциальные факторы, влияющие на меры реагирования. Ниже приведены наиболее часто наблюдаемые причины пересмотра плана реагирования:
- выявление ранее неизвестных командных серверов или новых шаблонов поведения в результате реверс-инжиниринга;
- новые криминалистические находки, включая скрытые задачи планировщика, артефакты в теневых копиях и «спящие» DLL-библиотеки;
- обнаружение дополнительных путей горизонтального перемещения на основе анализа сетевого трафика;
- человеческий фактор — недоступность владельцев систем, изменения в процессах управления или ожидание решения со стороны руководства.
Как показывает опыт, если команды рассматривают план реагирования как динамически меняющийся документ — регулярно дополняют его новыми артефактами, пересматривают приоритеты действий и актуализируют перед каждым этапом локализации угрозы — это снижает риск упущения критически важных мероприятий по ликвидации последствий. И наоборот, строгое следование первоначальному плану, составленному на основе ограниченного объема криминалистических данных, повышает вероятность того, что отдельные точки закрепления злоумышленников будут пропущены.
Разграничение артефактов реальных атак и следов тестирования на проникновение
Наконец, еще одна устойчивая проблема, наблюдавшаяся в 12% случаев, — сложность разграничения активности злоумышленников и артефактов легитимного тестирования на проникновение (пентеста). При поиску следов компрометации часто обнаруживаются следы легитимных инструментов тестирования, и не всегда можно однозначно определить, связан ли конкретный артефакт с реальным вторжением или с разрешенным пентестом. Основные факторы, затрудняющие это разграничение, таковы:
- Недостаточно документированные отчеты о пентесте и неполная очистка систем от его артефактов.
- Использование одних и тех же инструментов (например, SharpHound) как специалистами по пентесту, так и реальными злоумышленниками.
- Одновременное проведение мероприятий по поиску следов компрометации и активного пентеста, которое распыляет внимание аналитиков и увеличивает количество ложноположительных срабатываний. Хотя крайне важно сопоставлять результаты поиска следов компрометации с отчетами о пентесте, следует учитывать, что это исследовательский процесс, который проводится под контролем аналитиков. Артефакты, возникающие при симуляции атак в ходе пентеста, могут вводить аналитиков в заблуждение, что приведет к неверной интерпретации данных и снижению эффективности поиска следов компрометации.
Компетенции в области реагирования и их влияние на критичность инцидентов
Наши данные указывают на взаимосвязь между наличием внутренних компетенций в области цифровой криминалистики и реверс-инжиниринга вредоносного ПО и распределением уровней критичности инцидентов. В проектах по поиску следов компрометации за 2025 год соотношение инцидентов низкого, среднего и высокого уровней критичности заметно различалось между организациями, обладающими такими компетенциями, и теми, у кого они отсутствовали. Приведенные ниже данные иллюстрируют эту взаимосвязь и могут помочь оценить коммерческую ценность развития навыков реагирования внутри организации.
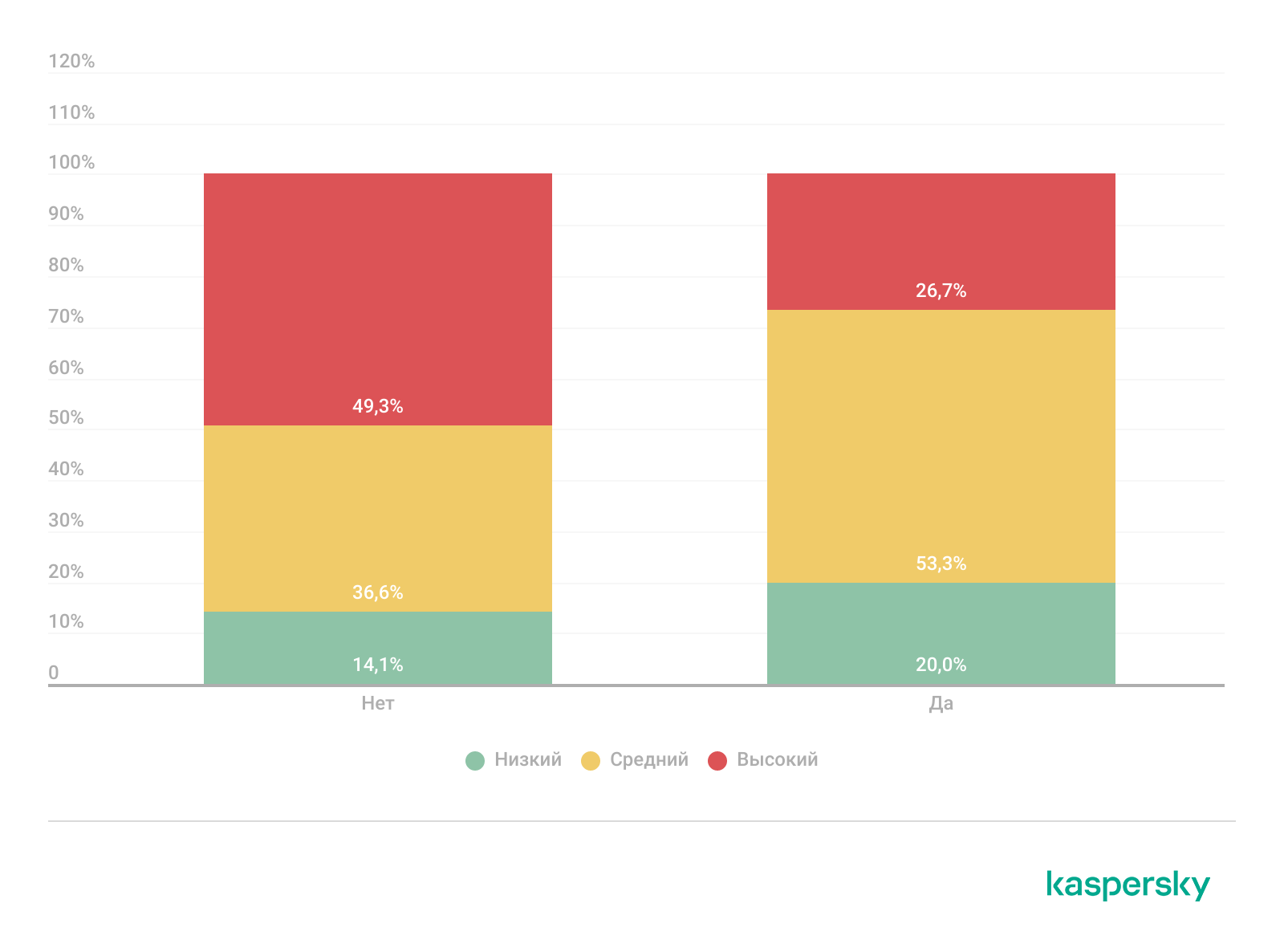
Серьезность инцидентов, требующих криминалистического анализа, при наличии или отсутствии соответствующих возможностей в организации
В организациях, обладающих возможностью самостоятельного анализа цифровых криминалистических артефактов, мы выявили вдвое меньше инцидентов высокой критичности и более высокую долю инцидентов низкой и средней критичности.
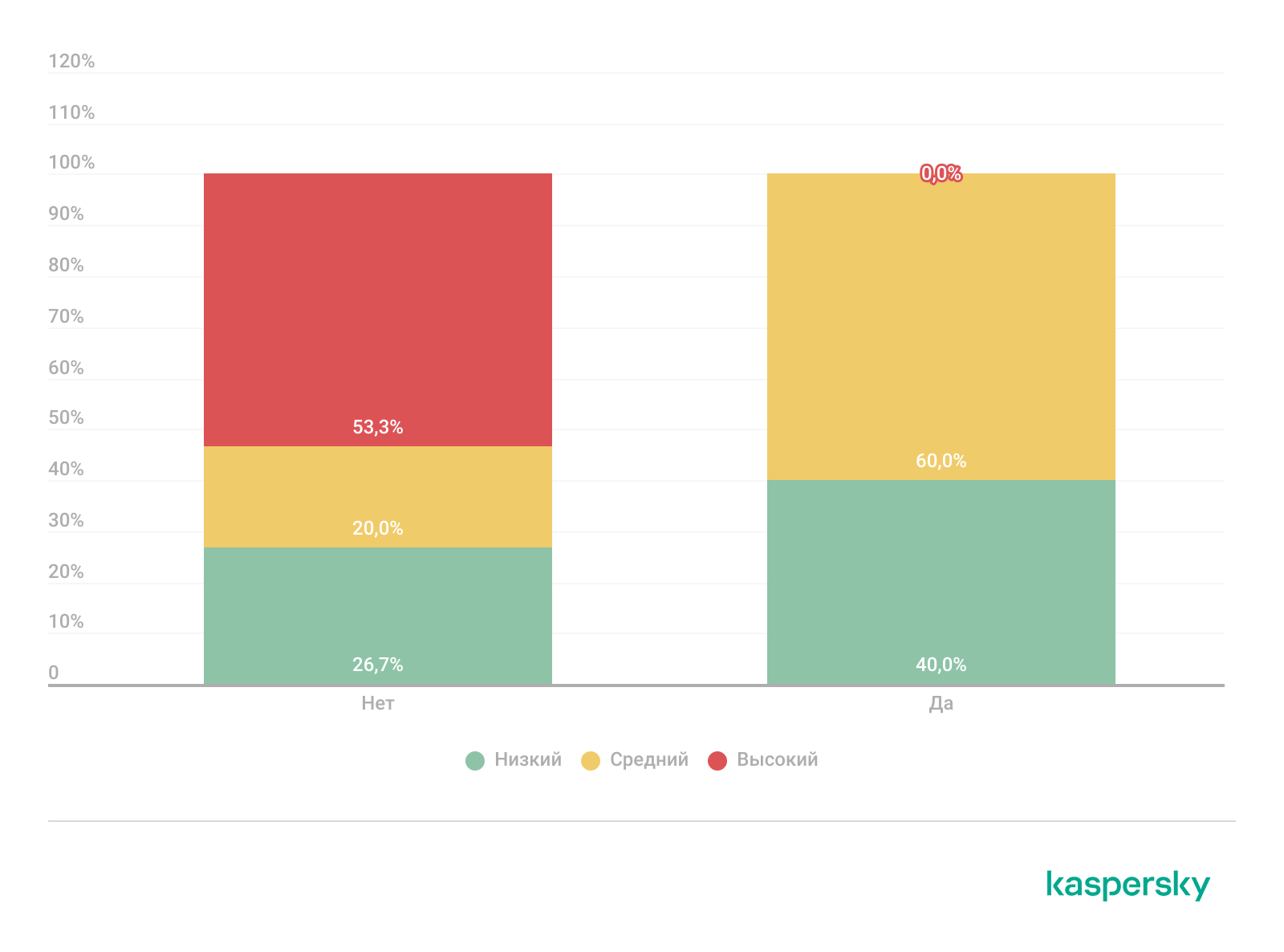
Серьезность инцидентов, требующих анализа вредоносного ПО, при наличии или отсутствии соответствующих возможностей в организации
В нашей выборке при наличии выделенного специалиста по реверс-инжинирингу случаи высокой критичности полностью отсутствовали; большинство инцидентов относились к средней категории, а также фиксировалось больше инцидентов низкой критичности.
Проанализировав эту статистику, со средней степенью уверенности можно предположить, что наблюдаемая разница в характере инцидентов вряд ли обусловлена размером выборки и скорее отражает реальный операционный эффект: внутренние компетенции в области цифровой криминалистики и анализа вредоносного ПО влияют не только на эффективность SOC, но и на общую киберустойчивость организации.
Пример из практики: вредоносное ПО LionTail, работающее в памяти на критически важных Windows-серверах
В ходе одного из проектов по поиску следов компрометации была выявлена устойчивая угроза, присутствующая в оперативной памяти на нескольких критически важных серверах. Она была связана с фреймворком LionTail — сложным набором кастомных загрузчиков и резидентных имплантов на основе шелл-кода. LionTail использует недокументированные особенности работы Windows-драйвера HTTP.sys для скрытой доставки полезной нагрузки через входящий HTTP-трафик, маскируя вредоносную активность под легитимные сетевые потоки.
Несколько обнаруженных экземпляров были связаны с группой Scarred Manticore, которая создает уникальный имплант для каждого скомпрометированного хоста и эксфильтрует данные, тщательно маскируя коммуникации с командными серверами под обычный сетевой трафик.
Угрозу удалось обнаружить по статической сигнатуре в оперативной памяти, выявленной внутри процесса scrcons.exe. Хотя scrcons.exe является легитимным исполняемым файлом WMI-хоста, расположенным в каталоге C:\Windows\System32\wbem, злоумышленники нередко внедряют в него полезную нагрузку, что позволяет выполнять код в памяти без привлечения внимания.

План реагирования включал ряд мер, наиболее критичные из которых перечислены ниже:
- сбор дампов оперативной памяти для углубленного анализа;
- получение полных криминалистических образов дисков затронутых систем;
- детальный анализ собранных артефактов и последующее обновление плана реагирования на инциденты.
Организации было сложно реализовать эти мероприятия из-за ограниченных возможностей в области цифровой криминалистики и реверс-инжиниринга. Для реагирования на инциденты, связанные с бесфайловыми угрозами, выполняющимися в памяти, эти компетенции являются обязательными. Без них организации рискуют утратить важные улики, неверно оценить масштаб компрометации или не суметь полностью устранить сложные импланты, оставляющие минимальные следы на диске.
Хотя наши специалисты смогли завершить расследование и локализовать угрозу, этот случай выявил недостаточный уровень готовности организации. Он продемонстрировал, что зависимость от внешней помощи в высококритичных инцидентах представляет собой конкретный операционный риск, и подтвердил важность наличия в штате опытных специалистов в области цифровой криминалистики и реверс-инжиниринга для своевременного, точного и всестороннего устранения инцидентов.
Поиск первопричин инцидентов
По завершении проекта по поиску следов компрометации мы переходим от этапа реагирования к этапу консультирования. Финальная встреча посвящена предотвращению повторных инцидентов: на ней обсуждаются первопричины, по которым атака осталась незамеченной. Предоставляемые рекомендации ориентированы на практическую реализацию и учитывают особенности среды заказчика. Для целей данного отчета мы сгруппировали их по категориям.
| Категория первопричин | Доля инцидентов | Типовые заключения |
| Недостаточная точность обнаружения | 60,7% | • Решения EPP/EDR или связанные с ними источники логов событий не генерировали надежные оповещения. • В 9,4% случаев продукт был неправильно настроен, устарел или функционировал некорректно. |
| Отсутствие мониторинга на основе оповещений | 35,9% | • Оповещения, которые могли указывать на компрометацию, были сгенерированы, но инцидент не был зарегистрирован. • Сигналы с высоким уровнем неопределенности (например, эвристическое обнаружение веб-шеллов) требовали проверки аналитиком. |
| Недочеты в управлении уязвимостями и конфигурациями | 28,2% | • Были допущены очевидные ошибки в конфигурации (например, отключение логов аудита или служебные учетные записи с избыточными привилегиями). • Известные уязвимости оставались неисправленными, либо не были приняты меры по снижению связанных с ними рисков. |
| Отсутствие структурированных процессов активного поиска угроз | 27,4% | • Оповещения с низким уровнем достоверности не перепроверялись после первоначального отсеивания. • Значительные объемы телеметрии оставались необработанными из-за нехватки персонала. |
| Неэффективные программы повышения осведомленности в сфере ИБ | 25,6% | • На утечки учетных данных с личных устройств сотрудников или подрядчиков пришлось 27,2% инцидентов, связанных с недостаточной осведомленностью в вопросах безопасности. • Попытки социальной инженерии оказались успешными из-за недостаточной подготовленности пользователей к таким атакам. |
| Отсутствие задокументированных политик или процессов | 23,9% | • Отсутствовали формализованные сценарии реагирования на инциденты, процедуры управления изменениями и регламенты работы с данными. |
Основные выводы по первопричинам
Проверка работоспособности систем обнаружения была наиболее частой корректирующей мерой. Более чем в половине случаев, когда оповещения отсутствовали, для устранения этого пробела рекомендовалось выполнить базовую проверку работоспособности сенсоров и актуальности правил. Без такой проверки невозможно было оперативно определить, связано ли отсутствие оповещений с инцидентом или с настройками самого продукта.
Оповещения с низким уровнем достоверности по-прежнему должны обрабатывать аналитики вручную. Автоматизированная обработка не способна компенсировать работу правил, склонных к ложным срабатываниям (например, общую эвристику для обнаружения веб-шеллов). Для сокращения времени присутствия злоумышленников в сети рекомендуется внедрение этапа ручной сортировки входящих сигналов об угрозах.
Нехватка налаженных процессов (управления уязвимостями, активного поиска угроз, политик безопасности) занимает значительную долю среди первопричин инцидентов. Даже в зрелых организациях сохраняются пробелы в рутинных процессах, которые могут быть устранены с помощью четко регламентированных рабочих процедур. Отсутствие задокументированных политик и процессов стало первопричиной инцидентов в 23,9% случаев.
Актуальный пример непродуманных политик безопасности — разработка ПО с помощью генеративного ИИ без четких правил обработки данных. В ходе одного из проектов мы нашли рабочую станцию на базе macOS, где ассистент Claude Code (Anthropic) с интерфейсом командной строки использовался как расширение VS Code. Инструмент автоматически регистрировал состояние файловой системы для обогащения промптов языковой модели.
Полученные образы включали полные списки каталогов и абсолютные пути к нескольким рабочим книгам Excel, содержащим конфиденциальные внутренние данные:
| Командная строка родительского процесса | Командная строка |
| /bin/zsh -c -l source /Users/[СКРЫТО]/.claude/shell-snapshots/snapshot-zsh-[СКРЫТО].sh && eval ‘ls -lh «/Users/[СКРЫТО]/Documents/[СКРЫТО]/»*.xlsx‘ \\< /dev/null && pwd -P >| /var/folders/[СКРЫТО]/claude-[СКРЫТО] | ls -lh /Users/[СКРЫТО]/Documents/[СКРЫТО].xlsx /Users/[СКРЫТО]/Documents/[СКРЫТО].xlsx /Users/[СКРЫТО]/Documents/[СКРЫТО].xlsx .. [СКРЫТО] |
Мы рекомендовали организации провести для сотрудников ряд обучающих занятий, направленных на повышение осведомленности о рисках раскрытия внутренней конфиденциальной информации при использовании инструментов генеративного ИИ, а также разработать политику, регулирующую применение таких инструментов при работе с чувствительными данными.
Проблемы с обнаружением: причины и последствия
Проекты по поиску следов компрометации раз за разом показывают, что недостаточный охват детектирования существенно влияет на долю инцидентов высокой критичности. В случаях, когда охват детектирования оценивался как низкий, 52% инцидентов классифицировались как высококритичные, и лишь 15% имели низкую критичность. Такое распределение указывает на взаимосвязь: ограниченная видимость, судя по всему, увеличивает долю инцидентов, перерастающих в компрометации высокой степени критичности.
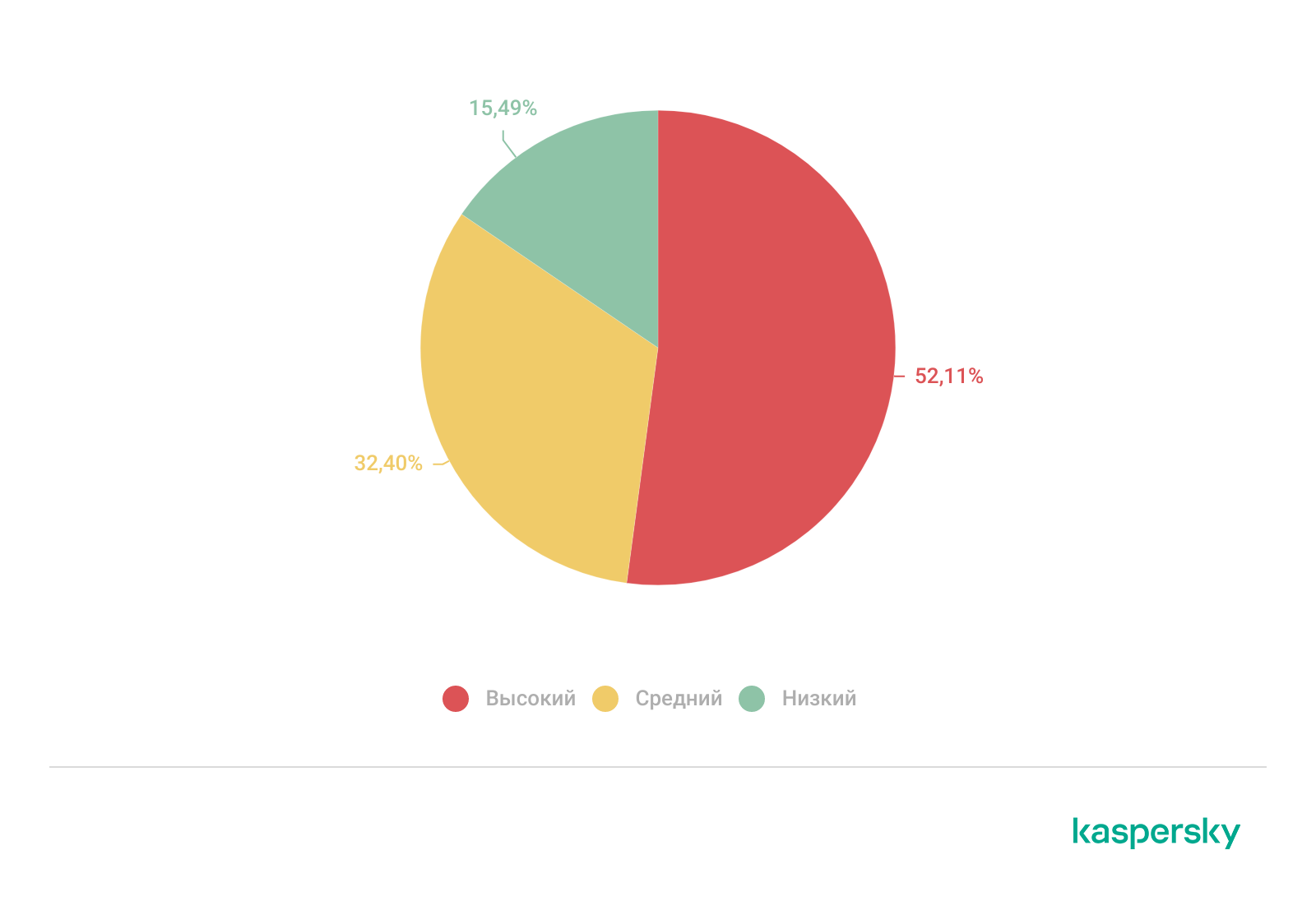
Распределение критичности инцидентов, причиной которых было недостаточное детектирование текущими средствами защиты
Существует распространенное мнение, что зрелость процессов обнаружения можно повысить за счет привлечения поставщика управляемых услуг безопасности (MSSP). Однако наши данные демонстрируют менее однозначную картину. Даже при использовании MSSP 26,5% инцидентов оставались невыявленными в связи с отсутствием достаточного детектирования, а примерно в 50% проектов с участием MSSP наблюдались очевидные пробелы в аудите Windows (например, отсутствие сбора логов событий или отключенные политики аудита).
Как показывает статистика, один лишь аутсорсинг не гарантирует эффективности обнаружения — необходимы активное участие в управлении и непрерывная валидация. К обнаружению следует относиться как к развиваемой функции, требующей постоянных тестирования, оценки и совершенствования независимо от того, осуществляется ли она собственными силами или передана внешнему провайдеру.
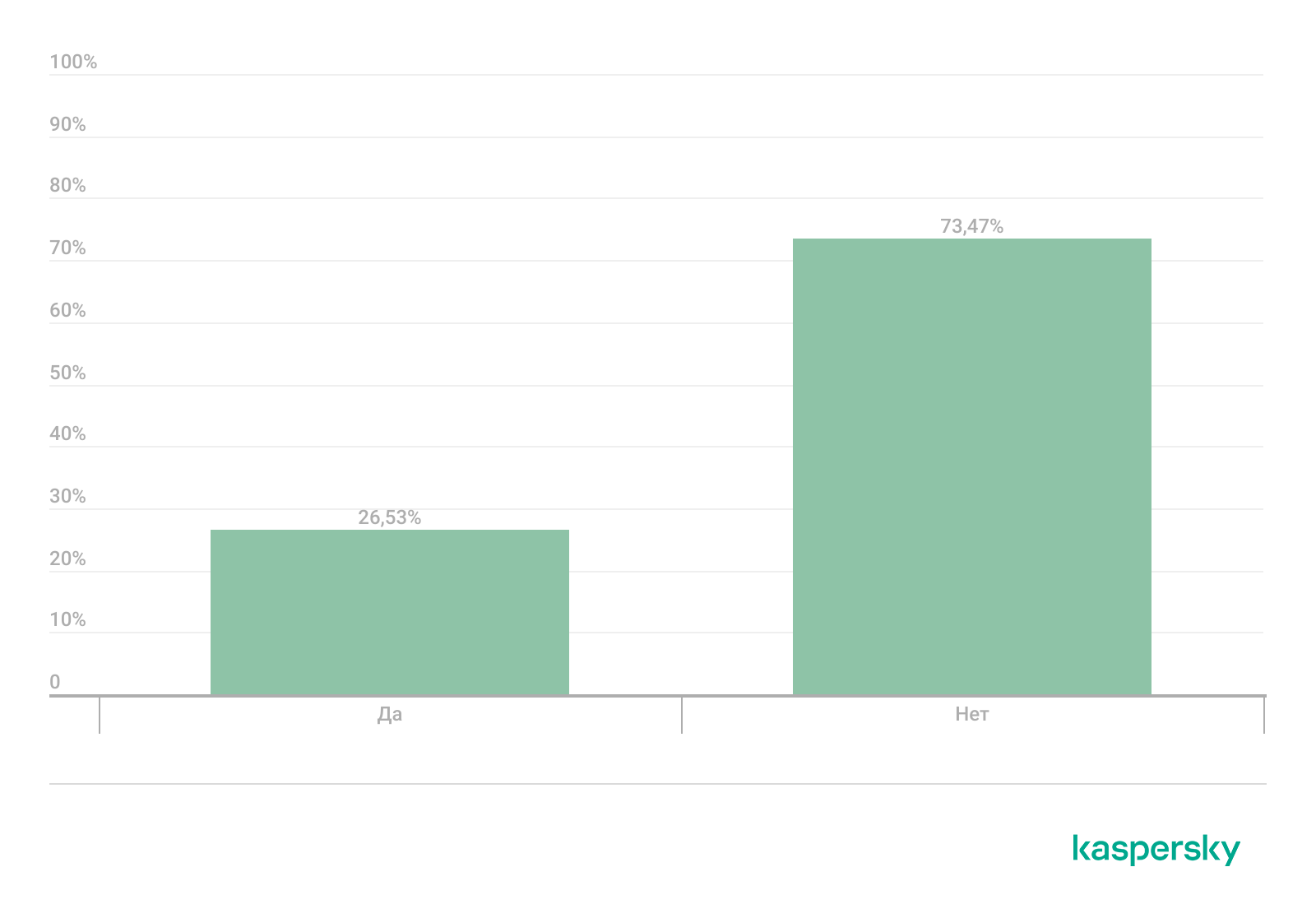
Распределение инцидентов, пропущенных из-за отсутствия возможностей обнаружения, между организациями, которые используют и не используют услуги MSSP
Анализ первопричин пропущенных инцидентов выявляет несколько повторяющихся закономерностей. Во многих средах есть необходимые технологии, но плохо выстроены процессы их эксплуатации. Основные проблемы заключаются в следующем:
- Отсутствие проверки работоспособности платформы для защиты рабочих мест (EPP) — в проектах, где такая проверка проводилась слабо или отсутствовала, почти 50% инцидентов перерастали в категорию высокой критичности. Это классический случай, когда решение развернуто и заброшено: агенты установлены, но могут быть некорректно настроены, не обновлены или не валидированы.
- Нехватка актуальных данных об угрозах — при отсутствии доступа к потоку или платформе данных об угрозах (threat intelligence) около половины инцидентов достигали высокой степени критичности. Без верифицированных индикаторов компрометации и контекстного обогащения аналитики вынуждены полагаться на стандартные оповещения и могут упустить вредоносные действия, связанные с известными угрозами.
В основе этой проблемы лежит менталитет «настроил и забыл», подразумевающий только реагирование на оповещения: организации полагают, что внедренные инструменты обеспечивают защиту автоматически, даже если их конфигурация не контролируется, работоспособность не валидируется, а актуальные данные об угрозах не поступают.
| Распределение инцидентов по степени критичности при отсутствии проверки работоспособности EPP или потоков аналитических данных об угрозах | |||
| Отсутствующий элемент безопасности | Высокая критичность | Средняя критичность | Низкая критичность |
| Проверка работоспособности EPP | 48,3% | 36,7% | 15% |
| Поток аналитических данных об угрозах | 50% | 40% | 10% |
Неспособность обнаружить угрозу редко обусловлена отсутствием какого-то одного компонента защиты. Как правило, это сочетание слабой конфигурации, недостаточного сбора телеметрии и отсутствия регулярных проверок и процессов, подтверждающих фактическую работоспособность средств защиты, — особенно в аутсорсинговых моделях. Гибридный подход к мониторингу, сочетающий внутренний контроль с внешней поддержкой MDR или MSSP, неизменно демонстрирует свою эффективность как наиболее устойчивая модель — при условии четкого определения ролей, ожиданий и метрик эффективности. Обнаружение угроз следует рассматривать как постоянно развивающуюся функцию, а не как результат разовой закупки защитных решений.
Чтобы проиллюстрировать реальные последствия недостаточного контроля над средствами безопасности, рассмотрим серьезный инцидент, который оставался незамеченным на протяжении нескольких месяцев исключительно из-за отсутствия в организации необходимых механизмов обнаружения.
Пример из практики: заражение зловредом PurpleFox, функционирующим в оперативной памяти, в обход традиционных средств защиты рабочих мест
В ходе проекта по поиску следов компрометации мы выполнили сканирование оперативной памяти исследуемых хостов с использованием набора правил, предназначенного для активного поиска угроз. В результате удалось найти два скрытых объекта:
- код руткита PurpleFox, внедренный в легитимные процессы svchost.exe на нескольких критически важных серверах;
- сигнатуры криптовалютного майнера XMRig внутри тех же скомпрометированных экземпляров svchost.exe.
PurpleFox оставляет в системе специально подготовленные DLL-библиотеки и принудительно загружает их через процесс svchost.exe; они, в свою очередь, устанавливают драйвер режима ядра, обеспечивающий злоумышленнику скрытное закрепление в системе с возможностью незаметного запуска и загрузки дополнительных полезных нагрузок, включая упомянутый майнер XMRig.
Развернутое решение EPP отслеживало создание файлов, изменения реестра и сетевые подключения, однако его модуль анализа оперативной памяти был отключен. Набор сигнатур, который использовался на момент проведения поиска следов компрометации, также был устаревшим. В результате внедренные DLL-библиотеки и шелл-код майнера не генерировали никаких оповещений. На этапе анализа оперативной памяти наша команда выявила проблему в конфигурации систем обнаружения и зафиксировала отсутствие функции проверки памяти в итоговом отчете.
Обеспечение безопасности организация передала на аутсорсинг MSSP-провайдеру, который собирал логи и направлял их в SIEM-систему. Поскольку исходные логи не содержали сигналов об активности в оперативной памяти, деятельность PurpleFox не была выявлена.
Ненадлежащее управление уязвимостями — катализатор высококритичных инцидентов
Более половины инцидентов, выявленных в ходе проектов по поиску следов компрометации в 2025 году и связанных с некачественным управлением уязвимостями или отсутствием исправлений, имели высокий уровень критичности. Чаще всего они приводили к развертыванию веб-шеллов, обеспечивающих закрепление и возможность удаленного выполнения кода, а также к эксплуатации неправильно настроенных служб Active Directory.
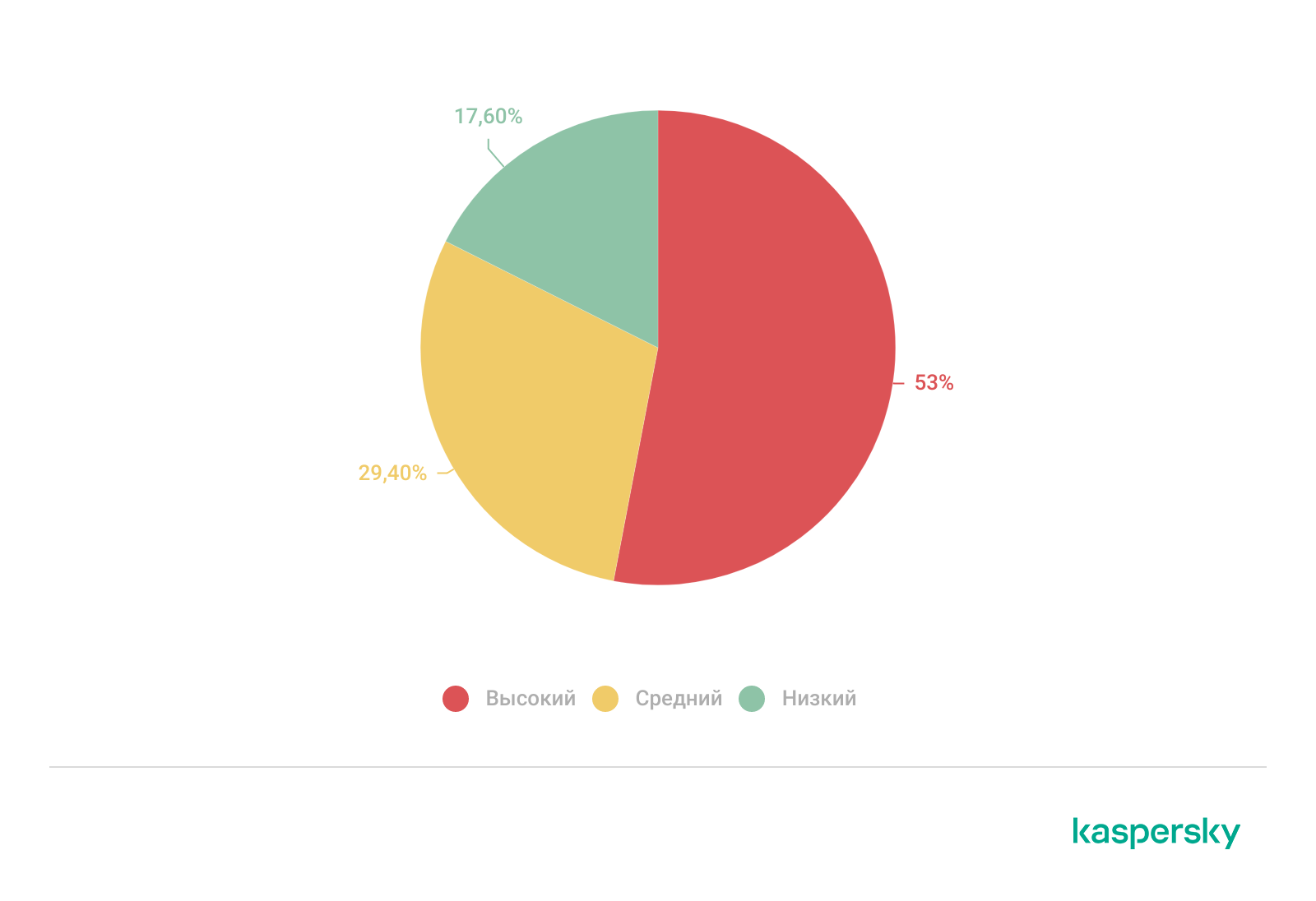
Распределение инцидентов по критичности при ненадлежащем управлении уязвимостями
Причины отсутствия исправлений могут быть самыми разными, включая недостаточную инвентаризацию активов (зафиксировано в 25% проектов) и отсутствие формализованных процессов управления уязвимостями (41% проектов). Более того, у 86% организаций, заявивших о наличии программы управления уязвимостями, при поиске следов компрометации все равно обнаруживались эксплуатируемые злоумышленниками ошибки конфигурации. Эти наблюдения показывают, что эффективное управление исправлениями, полная инвентаризация активов и четко структурированные процессы управления уязвимостями имеют решающее значение для предотвращения инцидентов высокой критичности.
Пример из практики: типичный пример последствий избыточных прав при распространении ПО через GPO
В разных проектах по поиску следов компрометации мы регулярно сталкивались со следующей критической ошибкой конфигурации: через объект групповой политики (GPO) задавался путь к исполняемому файлу в общей сетевой папке, который запускался на каждой рабочей станции посредством запланированного задания. При этом к данной сетевой папке был предоставлен полный доступ всем пользователям через список контроля доступа (ACL).
Поскольку в эту сетевую папку может записывать файлы любой аутентифицированный пользователь, злоумышленнику достаточно скомпрометировать одну низкопривилегированную учетную запись, чтобы заменить легитимный исполняемый файл на свою полезную нагрузку. При следующем запуске задания вредоносный файл автоматически попадет на все конечные устройства, на которые распространяется соответствующая групповая политика, обеспечивая:
- повышенные права в контексте выполнения: запланированное задание часто выполняется от имени SYSTEM или локального администратора;
- автоматическое распространение: вредоносный исполняемый файл распространяется без дополнительной эксплуатации сетевых уязвимостей;
- потенциальное повышение привилегий: компрометация низкопривилегированной учетной записи может привести к выполнению кода с правами администратора домена.
Если бы организация следовала процедурам управления уязвимостями, включающим систематический аудит разрешений GPO и сетевых папок, возможность записи в такую директорию была бы классифицирована как критическая проблема и устранена до начала атаки. Для устранения этой проблемы, как правило, достаточно ограничить права авторизованных пользователей только чтением и выдать права на изменение строго ограниченному кругу привилегированных учетных записей. Включение подобных проверок в базовые механизмы контроля безопасности снижает поверхность атаки и существенно уменьшает риски при надлежащем проведении аудита и тестирования на проникновение (VAPT).
Заключение
За 2025 год специалисты сервиса Kaspersky Compromise Assessment помогли организациям выявить ряд давних, ранее незамеченных угроз: следы активности в 30,8% инцидентов охватывали период более трех месяцев, при этом среди инцидентов высокой критичности таких случаев было 52%. Из всех обнаруженных отсутствия инцидентов 20% были найдены вручную, а 60% угроз не были замечены организациями из-за отсутствия надежных оповещений от существующих средств защиты. Возраст самого давнего незамеченного инцидента, выявленного командой Kaspersky Compromise Assessment в 2025 году, составлял около четырех лет.
На постинцидентные проверки приходилась наибольшая доля инцидентов высокой критичности, тогда как регулярные превентивные аудиты, проверки соответствия требованиям и аудиты перед объединением двух сетей, как правило, позволяли выявлять проблемы на более ранних стадиях. Это указывает на то, что исключительно реактивные расследования часто не обнаруживают скрытые механизмы закрепления злоумышленников в системе. Обобщив опыт всех проектов 2025 года, для повышения безопасности обычно мы рекомендуем организациям:
- провести комплексную проверку работоспособности модулей детектирования в течение 30 дней после завершения проекта, уделив приоритетное внимание целостности телеметрии и актуальности правил;
- создать команду валидации оповещений первого уровня, которая будет регулярно проверять все события с низким уровнем достоверности по установленному графику;
- организовать тщательный круглосуточный мониторинг и усилить его активным поиском угроз, ориентированным на базовые профили активности, оповещения с низкой точностью и новые техники злоумышленников;
- пересмотреть процессы управления уязвимостями и обеспечить регулярное внедрение исправлений и полноценное ведение логов аудита на всех критически важных активах;
- обновить программы повышения осведомленности в области информационной безопасности, уделив особое внимание утечкам учетных данных с личных устройств и практике безопасного использования персональных устройств для работы (BYOD);
- регулярно проводить тренинги в формате ролевой игры для отработки сценариев реагирования, повышения квалификации команд и улучшения коммуникаций;
- разработать соглашения об уровне операционной поддержки (OLA), регламентирующие взаимодействие между командами, а также стандартные операционные процедуры (SOP) для корректного документирования.
Систематическая работа над перечисленными категориями первопричин поможет организациям снизить вероятность появления слепых зон в будущем и повысить общий уровень защищенности.
Содержание
- Ключевые тенденции, выявленные в завершенных проектах Kaspersky Compromise Assessment
- О работе сервиса Kaspersky Compromise Assessment
- Причины обращений в Kaspersky Compromise Assessment
- Незамеченные давние инциденты
- Ненамеренное сохранение вредоносных компонентов
- Легитимные, но подозрительные: инструменты удаленного управления и LoLBin-утилиты
- Отсутствие постоянного мониторинга и превентивного поиска угроз
- Статистика реагирования на инциденты
- Почему реагирование чаще всего начинается со сбора криминалистических данных
- Сдерживание угрозы: проблемы корректного удаления файлов и записей реестра
- Коммуникационные проблемы как дополнительная операционная сложность
- Итеративное обновление плана реагирования
- Разграничение артефактов реальных атак и следов тестирования на проникновение
- Компетенции в области реагирования и их влияние на критичность инцидентов
- Поиск первопричин инцидентов
- Основные выводы по первопричинам
- Проблемы с обнаружением: причины и последствия
- Ненадлежащее управление уязвимостями — катализатор высококритичных инцидентов
- Заключение
От тех же авторов




В той же категории












Незамеченные инциденты, устойчивые угрозы и проблемы реагирования: анализ проектов Kaspersky Compromise Assessment