

Технологии машинного обучения (Machine Learning, ML) в нашей компании часто используются для повышения качества систем кибербезопасности. Однако мы понимаем, что модели машинного обучения могут быть подвержены ряду атак, направленных на то, чтобы модель систематически допускала ошибки в работе. Это может привести к значительному ущербу как для нашей компании, так и для наших клиентов. Поэтому нам особенно важно знать, какие у наших ML-решений потенциальные уязвимости и как не допускать того, чтобы ими воспользовались злоумышленники.
В данной статье мы расскажем про то, как мы атаковали собственную ML-технологию DeepQuarantine, которая является частью нашей антиспам-системы, и какой способ защиты от подобных атак мы реализовали. Но сначала давайте подробнее рассмотрим саму технологию.
Технология DeepQuarantine
DeepQuarantine — нейросетевая модель, предназначенная для обнаружения подозрительных писем и отправки их на карантин. Она позволяет выиграть время для обновления спам-фильтров и проведения повторной проверки. Если проводить аналогию, то процесс работы DeepQuarantine можно сравнить с работой сотрудника пограничной службы в аэропорту. Если пассажир выглядит подозрительно, сотрудник отправляет его на дополнительную проверку. Пока пассажир ожидает, служба безопасности досматривает его багаж и проверяет документы. Если проверка пройдена, то пассажир отправляется дальше, если нет — он будет задержан. В случае с антиспам-системой в роли службы безопасности выступают антиспам-эксперты и сервисы, которые обрабатывают большие потоки спама и создают новые детектирующие правила, пока письмо находится на карантине, а в роли вещей и документов пассажира, которые досматривает служба безопасности, — заголовки письма. Если анализ заголовков выявляет признаки спам-письма, по его результатам создается детектирующее правило. Кроме того, пока письмо находится на карантине, база правил может расшириться в результате анализа других писем. После того как письмо выходит из карантина, оно проходит повторную проверку, и если обновленные за время карантина правила срабатывают на нем, то оно попадает в спам, а если нет — доставляется клиенту. Стоит сказать, что технология, принимающая решение об отправке письма на карантин, должна быть очень точной, чтобы не задерживать легитимные письма. Как и в случае с аэропортом, где сотрудник пограничной службы не может отправлять на досмотр всех пассажиров, поскольку это помешало бы регулярному отправлению рейсов.
Более подробно о том, как работает DeepQuarantine, можно прочитать в этой статье. Для успешной атаки на модель необходимо знать две вещи: 1) какие признаки она использует при принятии решения, 2) как формируются данные для ее обучения.
В качестве признаков, по которым определяются подозрительные письма, наша модель использует последовательность технических заголовков (для примера, на рисунке 1 значение этого признака равнялось бы «Subject:From:To:Date:Message-Id:Content-Type:X-Mailer»), а также содержимое полей Message-Id (уникальный идентификатор сообщения) и X-Mailer (название почтового клиента). Эти признаки были выбраны потому, что они зависят от типа используемого почтового клиента и потенциально могут хранить в себе «следы» спамера.

Рисунок 1. Технические заголовки электронного письма
Для иллюстрации работы алгоритма обратимся к примеру на рисунке 2. Слева письмо от PayPal, справа подделка под платежный сервис. Одним из обязательных заголовков для передачи почты является идентификатор Message-Id, формат которого зависит от почтового агента. Если сопоставить заголовки поддельного письма с оригинальным, то в глаза бросаются отсутствие домена и случайная последовательность символов и регистров в этом поле.

Рисунок 2. Сравнение заголовков реального и поддельного письма от PayPal
Такие и другие «следы» оставляют за собой мошенники в различных технических заголовках писем, которые обрабатывает модель и для которых не так просто создать аналитические правила.
Теперь рассмотрим процесс формирования данных для обучения, который и стал в итоге отправной точкой для реализации атаки на нашу модель.

Рисунок 3. Схема формирования обучающей выборки
Данные и разметка для обучения модели формируются автоматически в процессе работы антиспам-системы в целом. После проверки писем антиспам-сервис отправляет их заголовки и вердикты по ним в Kaspersky Security Network (KSN), если клиент дал согласие на обработку данных. Из KSN эта информация отправляется в хранилище, откуда впоследствии берутся данные для обучения модели. При этом в качестве образцов для анализа используются заголовки писем, а в качестве разметки — вердикты от антиспам-движка.
Атака на модели машинного обучения
Почему возможны атаки на модели машинного обучения? Во многом потому, что при использовании методов машинного обучения ожидается, что распределение данных в обучающей выборке будет соответствовать распределению данных, с которым модель сталкивается в реальном мире. Нарушение этого принципа может привести к неожиданному поведению алгоритма. Соответственно, можно выделить два типа атак на модели машинного обучения:
- Adversarial inputs — генерация таких входных данных, которые заставляют уже обученную и развернутую модель выносить неверный вердикт.
- Data poisoning (отравление данных) — влияние на обучающую выборку с целью получения смещенной модели.
В первом случае для эффективной атаки злоумышленнику зачастую необходимо напрямую взаимодействовать с моделью. DeepQuarantine является лишь одним из компонентов антиспам-системы, поэтому напрямую взаимодействовать с ней невозможно. Атака второго типа намного опаснее для нашей модели, ее мы и рассмотрим далее.
Атаки типа data poisoning можно разделить еще на два подтипа:
- Model skewing — загрязнение обучающей выборки с целью смещения у модели границы решения. В качестве примера такой атаки можно назвать атаки на классификатор спама компании Google, в которых продвинутые группы спамеров попытались загрязнить обучающую выборку, отмечая большое количество спама как «не спам». Если бы они были успешными, система стала бы пропускать больше спам-рассылок.
- Backdoor attack — внедрение в обучающую выборку примеров с определенными метками с целью заставить модель принимать неверное решение после обучения, но только при возникновении данной метки. Например, внедрить в картинки, которые принадлежат определенному классу (скажем, собаки), серый квадратик, чтобы впоследствии модель распознавала собаку, когда видит этот квадратик. При этом на картинке может быть совсем не собака.
Снизить риск успешной атаки типа data poisoning можно несколькими способами:
- Контролировать, чтобы входные данные из незначительного числа источников (например, от небольшой группы пользователей или IP-адресов) не составляли значительную часть обучающей выборки. Это может усложнить спамерам реализацию подобной атаки, поскольку им придется предпринимать дополнительные действия, чтобы их манипуляции не отбраковали как статистический выброс.
- Перед релизом обновленной версии модели сравнивать ее с последней стабильной версией с помощью различных методик, таких как A/B-тестирование (сравнение версий с разными изменениями в тестовой среде), dark launch (запуск обновленного сервиса для небольшой пилотной группы клиентов) или backtesting (тестирование модели на исторических данных).
- Создать контрольный набор данных, для которых известен правильный результат оценки и на которых проверяется точность работы модели.
Атака на DeepQuarantine
Теперь перейдем к атаке на DeepQuarantine. Допустим, цель злоумышленника — чтобы письма конкретной организации, например конкурента его работодателя, попадали на карантин. Это приведет к задержкам в доставке писем, что существенно повлияет на бизнес-процессы жертвы. Итак, рассмотрим шаги злоумышленника:
- Узнать, каким агентом пользуется компания-жертва, чтобы определить, какой тип заголовков генерируется при отправлении писем от данной компании.
- Сгенерировать спам-письма с заголовками, которые похожи на заголовки компании-жертвы. В тело письма добавляются какие-нибудь явные триггеры для спам-фильтров — например, откровенно рекламный текст или известные фишинговые ссылки, чтобы письма были точно помечены как спам.
- Разослать модифицированные письма нашим клиентам, чтобы антиспам-система их заблокировала и статистика по этим письмам попала в обучающую и тестовую выборку согласно схеме на рисунке 3.
Если после обучения на «отравленной» выборке модель успешно пройдет тестирование, произойдет релиз атакованной модели, и письма компании-жертвы начнут попадать на карантин. Далее мы рассмотрим эксперименты с различными способами отравления данных.
Методология
Для эксперимента мы взяли чистые выборки обучающих и тестовых данных, состоящие из наборов заголовков писем с соответствующими им вердиктами антиспам-решения. В обе выборки мы добавляли отравленные образцы заголовков компании-жертвы с вердиктом «спам» в количестве 0,1, 1, 5 и 10% от размера выборки. Для каждого эксперимента доля отравленных данных в обучающей и тестовой выборке была одинаковой.
Мы обучали модель на отравленной обучающей выборке, после чего на тестовой выборке проверяли значения метрик precision (точность, доля верно выставленных положительных вердиктов от всех положительных вердиктов модели) и recall (полнота, доля верно выставленных положительных вердиктов от общего количества спамовых заголовков в выборке), а также степень уверенности модели в присвоении вердикта «спам» письмам компании-жертвы.
Эксперимент № 1. Model skewing
В первом эксперименте мы реализовали подход model skewing, как и в примере с атакой на антиспам-модель Google. Однако по сравнению с примером с Google мы немного усложнили задачу, поскольку нам нужно было смоделировать атаку на определенную компанию. В этом случае в поле Message-Id мы использовали домен выбранной компании (рисунок 4), но сам ID генерировали случайным образом, сохраняя только определенную длину, характерную для агента, который использует данная компания. Последовательность заголовков и поле X-mailer из почтового агента компании-жертвы мы не меняли.

Рисунок 4. Шаблон отравленного примера
Мы проанализировали, как меняются наши целевые метрики (precision и recall) на тестовом наборе данных в зависимости от доли отравленных данных относительно размера обучающей выборки. Результаты представлены на рисунке 5. Как можно увидеть из графика, целевые метрики практически не меняются относительно ситуации, когда в данных нет отравленных примеров. Это значит, что модель, обученная на отравленной выборке, могла бы попасть в релиз.
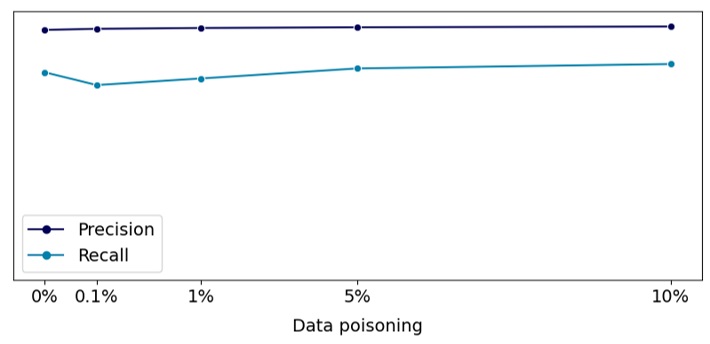
Рисунок 5. Целевые метрики в зависимости от количества отравленных данных
Мы также проверили на заголовках настоящих писем выбранной нами компании, как отравление выборки влияет на уверенность модели, что письмо должно быть отправлено на карантин.
Как видно из графика на рисунке 5, когда доля отравленных данных составляет более 5%, модель уже сильно уверена, что письма компании жертвы должны быть отправлены на карантин. Следовательно, такая смещенная модель может привести к коллапсу переписки этой компании с нашими клиентами, чего и добивается злоумышленник.
|
|
|
|
|
|
|
|
|
|


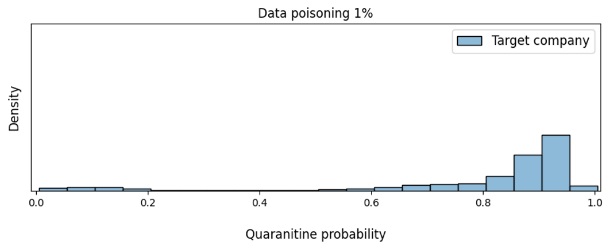

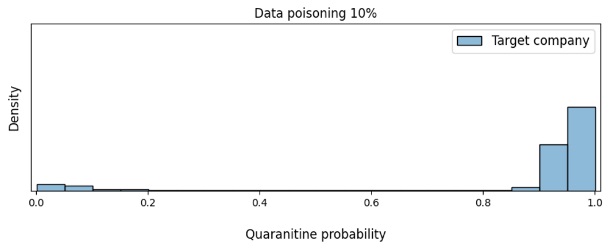
Рисунок 6. Изменение плотности (Density) уверенности модели в необходимости отправки писем компании-жертвы на карантин в зависимости от доли отравления данных
Теперь на примере тех объектов, для которых модель приняла неверное решение, посмотрим, на что она обращала внимание. Для этого мы построили карты значимости (Saliency Maps, см. рисунок 6) с помощью метода Saliency via Occlusion, при котором значимость тех или иных частей заголовков устанавливается путем поочередного скрывания этих частей и последующей оценки того, как при этом меняется уверенность модели. Чем темнее область на картинке, тем больше внимания нейронная сеть уделяет этой области при принятии решения. Также на рисунке представлено, какое количество писем выбранной компании (Target) и других компаний (Other) попадает на карантин.

Рисунок 7. Saliency Maps
Как видно из графиков, пока отравленных данных недостаточно, чтобы модель выдавала ложноположительный вердикт для писем компании-жертвы, модель концентрируется в основном на поле Message-Id. Но как только отравленных данных становится достаточно для смещения модели, мы видим, что ее внимание равномерно распределяется между Message-Id, полем X-mailer (MUA на графике) и последовательностью заголовков в письме (Header sequence).
Несмотря на то что для успешной атаки достаточно 5% отравления данных, в абсолютных показателях это довольно много. Например, если для обучения у нас используется более 100 млн писем, то злоумышленнику нужно будет отправить более 5 млн писем, что, вероятно, будет обнаружено системами мониторинга.
Можем ли мы более эффективно атаковать нашу модель? Оказывается, можем.
Эксперимент № 2. Backdoor attack с временной меткой
Некоторые почтовые агенты указывают временные метки в явном виде в поле Message-Id. Мы воспользовались этим, чтобы создать отравленные заголовки с временной меткой, которая соответствует дате релиза модели. В случае успешной атаки модель будет отправлять на карантин письма компании-жертвы, полученные в день релиза. Пример того, как именно мы генерировали отравленные данные, представлен на рисунке 8.

Рисунок 8. Бэкдор в данных в виде временной метки
Влияет ли такое отравление данных на целевые метрики при тестировании модели перед релизом? Результат тестирования оказался таким же, как и при атаке типа model skewing (рисунок 9).

Рисунок 9. Целевые метрики в зависимости от количества отравленных данных
Получилось ли у нас провести атаку более эффективно с точки зрения необходимого объема отравления данных? Как видно на рисунке 10, злоумышленнику в этом случае оказалось достаточно всего лишь 0,1% отравленных примеров, чтобы заставить модель считать подозрительными письма компании-жертвы.
|
|
|
|
|
|
|
|
|
|

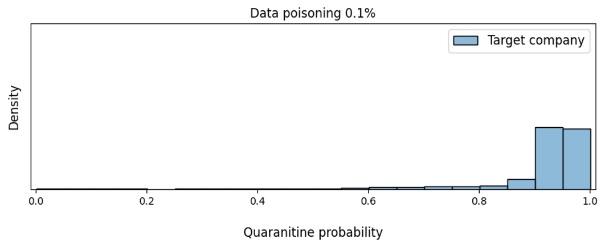



Рисунок 10. Изменение плотности (Density) уверенности модели в необходимости отправить письма компании-жертвы на карантин в зависимости от доли отравления данных
Снова взглянем на Saliency Maps, чтобы понять, на что в этом случае наша модель обращала внимание. На рисунке 11 видно, что при 0,1% отравления модель концентрирует внимание на зоне начала домена, типе агента и последовательности заголовков. При 1% отравления нейросеть максимально концентрируется на временной метке. Также можно заметить, что когда модель сконцентрирована только на временной метке, она выдает больше ложноположительных вердиктов и на письмах других компаний, у которых Message-Id тоже начинается с временной метки. При увеличении уровня отравления модель уже концентрирует внимание на части временной метки и зоне начала домена. При этом ее вообще не интересует поле X-mailer и последовательность заголовков в письме (Header sequence).
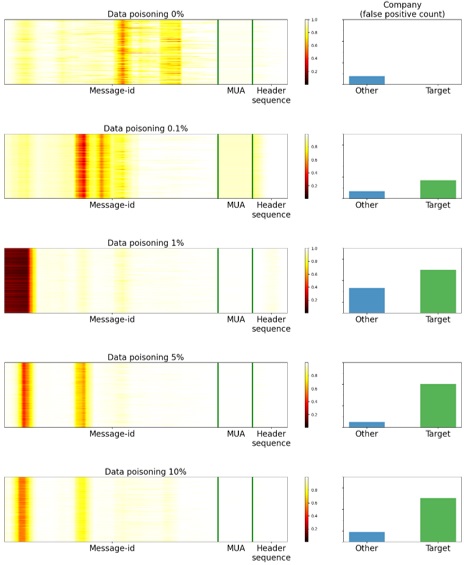
Рисунок 11. Saliency maps
Эксперимент № 3. Backdoor attack с временной меткой. Отложенная атака
В предыдущем эксперименте нам удалось значительно повысить эффективность атаки. Но в реальности маловероятно, что злоумышленник будет знать дату релиза модели. В данном эксперименте мы решили провести отложенную атаку и посмотреть, повлияет ли это на результаты тестирования. Для этого мы сгенерировали отравленные заголовки с временной меткой, которая сдвинута на год от текущей даты релиза (то есть не совпадает с ней).
Результаты представлены на рисунке 12: отравление выборки никак не отразилось при тестировании, что является наиболее опасным для нас, поскольку факт атаки в этом случае обнаружить практически невозможно. Учитывая, что «бэкдор» активируется в неопределенный момент в будущем, даже проведение dark launch и A/B-тестирования не поможет выявить атаку.
|
|
|
|
|
|
|
|
|
|




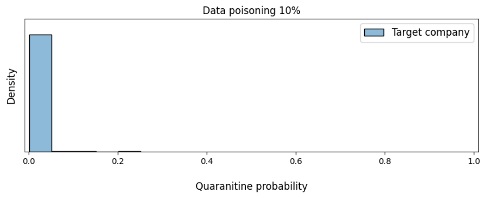
Рисунок 12. Зависимость уверенности модели в необходимости отправки писем компании-жертвы на карантин от доли отравления данных
По результатам экспериментов мы сделали следующие выводы:
- Model skewing требует достаточно большого количества отравленных образцов писем.
- Precision и recall не отражают факта атаки.
- Добавление «бэкдора» (в нашем случае — временной метки) позволяет проводить атаку более эффективно.
- Dark launch и A/B-тесты могут быть неэффективны при отложенной атаке.
Мы экспериментально продемонстрировали успешность атаки на нашу технологию. Но в связи с этим возникает вопрос: как мы защищаемся от подобного рода атак?
Защита от атак на ML-модель
В контексте наших экспериментов рассмотрим более подробно способы защиты от атак типа «отравление данных», о которых мы упоминали в разделе «Атака на модели машинного обучения»: контролируемый отбор данных для обучения, использование методик типа A/B-тестирования, dark launch или backtesting, а также создание аккуратно выверенного контрольного набора данных. Контролируемый отбор объектов для обучающей выборки действительно усложняет реализацию атаки, поскольку злоумышленникам приходится дополнительно продумывать, как отправить поддельные данные таким образом, чтобы их трудно было сгруппировать и отфильтровать. Это может быть технически сложно реализуемо, но, к сожалению, не невозможно. Например, чтобы отравленные письма нельзя было сгруппировать по IP-адресу, злоумышленник может воспользоваться ботнетом.
Если рассматривать создание дополнительного контрольного набора данных, на котором модель должна быть предельно точной, то в случае, когда распределение данных меняется со временем, возникает вопрос, насколько долго этот набор будет сохранять свою актуальность.
Сравнение обновленной модели с последней стабильно работающей версией выглядит более верным решением, так как позволяет отследить изменения в моделях. Но как их сравнивать между собой?
Рассмотрим два варианта, а именно сравнение версий модели на текущем тестовом наборе данных (Вариант 1) и сравнение версий модели на тестовых наборах данных, актуальных на момент релиза каждой из версий (Вариант 2). В таблице ниже представлена последовательность тестов, которые мы проводили для каждого из вариантов.
| Вариант 1 | Вариант 2 |
| Сравнение метрик качества | Сравнения метрик качества |
| Тесты для связанных выборок | Тесты для независимых выборок |
| Тесты на однородность | Тесты на однородность |
Сначала мы сравнили целевые метрики моделей. На этом этапе мы не увидели значимых различий между исходной и обновленной версией, обученной на выборке с различной долей загрязнения данных. Аналогичный результат мы получили и в ходе проведения экспериментальных атак.
На втором этапе сравнения моделей мы провели серию статистических тестов:
- T-критерий Стьюдента как для связанных, так и для независимых выборок
- Критерий Уилкоксона для связанных выборок
- Критерий Манна — Уитни для независимых выборок
- Критерий Колмогорова — Смирнова для проверки однородности выборок
В ходе экспериментов мы обнаружили интересную вещь: оказалось, что критерии выдавали значимые отличия даже при сравнении двух моделей, которые обучались на чистой выборке, хотя распределения предсказаний этих моделей не сильно различались между собой. Это происходило, поскольку при большом объеме данных тесты слишком чувствительны к малейшим изменениям в форме распределения. Но когда мы уменьшали количество данных в статистических тестах, то часто вообще не находили значимых различий, поскольку при сэмплировании письма, на которые была нацелена атака, могли вообще не попасть в выборку. Такой результат нас не устроил, и мы начали продумывать собственный критерий.
Мы отталкивались от того, что для моделей, обученных на чистой выборке, форма распределений на соответствующих тестовых наборах не сильно отличается. А в распределении предсказаний модели, обученной на отравленной выборке, могут появляться «горбики» ближе к правому концу распределения. На рисунке 13 мы специально изобразили большой «горбик» для наглядности. В реальности же он будет еле заметен, так как объем писем компании-жертвы может быть незначительным по сравнению с общим потоком писем.
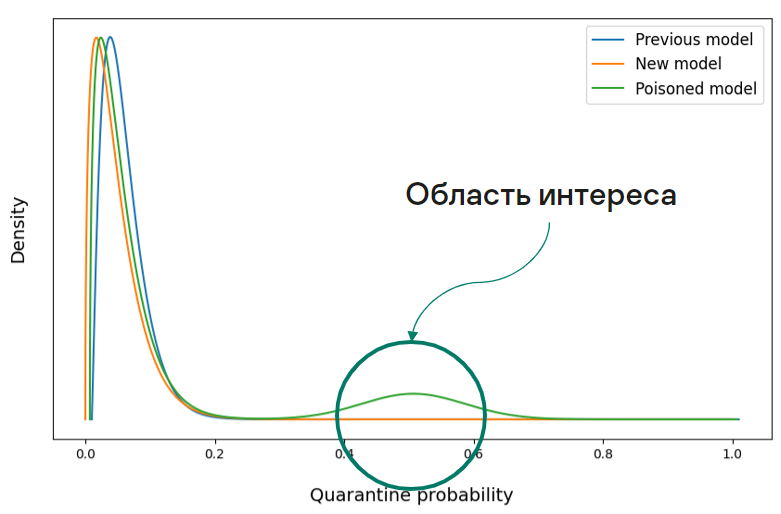
Рисунок 13. Cмоделированное распределение предсказаний модели на легитимных письмах
В ходе анализа мы пришли к метрике Вассерштейна. По сути данная метрика служит мерой расстояния между распределениями. Таким образом, наш критерий выглядит следующим образом:
H0: Распределения предсказаний на выборке из писем, не являющихся спамом, до и после обучения не показывают статистически значимых различий, то есть система осталась неизменной
H1: Различия в распределениях статистически значимые, то есть система претерпела изменения
Метрику Вассерштейна мы использовали для оценки различий между распределениями предсказаний старой и новой модели на выборке легитимных писем. Чтобы оценить статистическую значимость различий в распределении предсказаний, нам необходимо было узнать распределение этих различий при верной нулевой гипотезе, то есть для версий модели, не претерпевших значимых изменений. Мы получили данное распределение с помощью бутстрэпа, составив выборку из предсказаний моделей, обученных на чистых данных, но в разные временные периоды. Таким образом мы восстановили ситуацию в реальном мире. После этого мы провели ряд статистических проверок, сопоставляя распределения предсказаний исходной модели и модели, обученной на выборке с различной долей отравленных данных. Критерий Вассерштейна не показал значимых различий для нормальных моделей, а также для модели, которая обучалась на данных с отложенной атакой. Это вполне закономерно, поскольку мы видели, что отложенная атака никак не показывает себя на тесте. В остальных же случаях мы получили значимые различия. Это значит, что критерий Вассерштейна позволяет своевременно обнаруживать большинство атак подобного рода.
Что касается отложенных атак и вообще возможности внедрения метки-бэкдора в данные, то тут необходимо проводить детальный аудит данных на предмет возможных бэкдоров. А также тестировать модель машинного обучения на предмет устойчивости к такого рода атакам.
Выводы
Внедрение методов машинного обучения в различные сервисы становится все более обыденной вещью, поскольку оно позволяет достигать высоких показателей эффективности и улучшать жизнь пользователей. Однако это ведет и к появлению новых сценариев атак. Наш эксперимент показывает, что:
- Атаки типа data poisoning могут нанести существенный вред модели машинного обучения.
- Для проведения атаки не нужно быть специалистом в области науки о данных (Data Science).
- Временные метки могут быть легко использованы злоумышленниками в качестве бэкдора для атаки на модель машинного обучения.
- Стандартные метрики качества не отражают факт атаки типа data poisoning.
- Чтобы снизить вероятность успешной атаки на модель, необходимо контролировать процесс обучения и формирования выборок.
- Необходимо предельно аккуратно раскрывать детали обучения модели и ее архитектуру, чтобы злоумышленники не могли использовать их в своих целях.
- Перед релизом модели следует проводить тщательную проверку используемых критериев для принятия решения о готовности модели к релизу на предмет того, позволяют ли они обнаружить возможную атаку. Если существующие критерии не позволяют определить, была ли модель атакована, имеет смысл продумать собственный критерий, решающий эту проблему.
От тех же авторов

В той же категории












Как и зачем мы атакуем собственную антиспам-технологию?