

Авторы
Сценарий реагирования на инциденты — заранее определенный набор действий по устранению конкретных типов инцидентов безопасности: например, заражения вредоносным ПО, нарушения политик безопасности или DDoS-атаки. Главной целью использования таких сценариев является возможность для команды аналитиков оперативно и эффективно реагировать на любые киберугрозы. Сценарии реагирования помогают оптимизировать процессы в центре мониторинга и реагирования, что позволяет достигнуть высокой степени зрелости. Однако компании могут испытывать трудности с их разработкой. Поэтому мне хотелось бы поделиться советами по созданию идеального (или почти идеального) сценария реагирования.
Давайте представим, что злоумышленники используют фишинговые письма для проникновения в инфраструктуру компании, — это наиболее распространенный сценарий атаки. Какие действия должна выполнить команда реагирования на инциденты, чтобы остановить их? Во-первых, нужно установить факт присутствия злоумышленников в инфраструктуре и способ проникновения (например, через зараженное вложение в письме или скомпрометированную на поддельном веб-сайте учетную запись). Затем необходимо расследовать развитие атаки (проверить, какие техники использовались для закрепления и продвижения по сети), а затем принять меры по сдерживанию угрозы, чтобы снизить риски и возможный ущерб. Все эти действия необходимо выполнять быстро и безошибочно — ведь в случае сбоя технологических процессов, утечки данных, репутационных или финансовых потерь компания может серьезно пострадать.
Определение порядка действий — необходимый предварительный этап для разработки сценария
В разных организациях процесс реагирования на инциденты может включать в себя разные фазы. В этой статье я рассматриваю один из наиболее известных жизненных циклов реагирования на инциденты, разработанный Национальным институтом стандартов и технологий США (NIST). Он применяется во многих отраслях экономики, от банковской сферы до автомобильного производства.
Цикл состоит из следующих фаз:
- подготовка;
- обнаружение и анализ;
- сдерживание, устранение и восстановление;
- пост-инцидентный анализ.
Все фазы цикла описанные в NIST (или любые другие процессы реагирования на инциденты) можно разбить на так называемые блоки действий. Эти блоки в зависимости от характера атаки можно комбинировать в различные сценарии для наиболее быстрого и эффективного реагирования. Каждое действие представляет собой простую инструкцию, которую выполняет аналитик или автоматизированный скрипт в случае атаки. В предлагаемом подходе каждое действие представлено в виде структурного блока: <субъект> совершает <действие> над <объектом>, используя <инструмент>. Этот блок описывает, как команда реагирования или аналитик (<субъект>) выполняют конкретное <действие> с файлом, учетной записью, IP-адресом, хешем, ключом реестра и т. д. (<объектом>), используя системы, позволяющие выполнить такое действие (<инструмент>).
Определение действий в каждой фазе жизненного цикла инцидента, принятого в компании, обеспечивает согласованное реагирование и помогает создавать масштабируемые гибкие сценарии, которые можно быстро адаптировать к изменениям инфраструктуры или условий.

Пример стандартного действия в рамках реагирования
1. Подготовка к обработке инцидентов
Согласно жизненному циклу реагирования на инциденты NIST, первой фазой является подготовка. Обычно она состоит из множества разных этапов, включая предотвращение инцидентов (управление уязвимостями, обучение пользователей, предотвращение заражения вредоносным ПО и т. д.). Я рассмотрю этапы, связанные с разработкой сценариев и реагированием на инциденты. В первой фазе важно определить параметры оповещений и представление необходимых данных в карточке инцидента. Для каждого типа инцидентов имеет смысл подготовить разные наборы полей, наиболее подходящих в каждом случае.
Перед началом реагирования рекомендуется определить конкретные роли, участвующие в обработке, для каждого типа инцидента, а также сценарии эскалации. Кроме того, необходимо выбрать инструменты для взаимодействия с участниками процесса реагирования (например, электронная почта, телефон, мессенджеры или SMS). Команда реагирования должна получить необходимый уровень доступа к системам безопасности и IT-системам, ПО и интернет ресурсам для форензики (компьютерной криминалистики). Чтобы реагировать оперативно и не допускать ошибок вследствие человеческого фактора, необходимо разработать механизмы автоматизации и интеграции, запускаемые системой управления средствами безопасности и автоматизации реагирования на инциденты (SOAR).
2. Создание подходящих условий для расследования
Следующая важная фаза — обнаружение — включает в себя сбор данных из IT-систем и средств защиты, из общедоступных источников и от людей в организации и за ее пределами. Также определяются предпосылки и признаки атаки. И здесь прежде всего необходимо настроить систему мониторинга для обнаружения инцидентов определенных типов.
В фазе анализа я выделю несколько блоков: документирование, первичный анализ (triage), расследование и уведомление. Документирование помогает команде определить необходимые поля карточки инцидента для заполнения при его регистрации в системе управления инцидентами. После этого команда реагирования выполняет первичный анализ, чтобы приоритизировать и категоризировать инциденты (или скорректировать их, если они определяются автоматически), проверить на предмет ложноположительного срабатывания и найти связанные инциденты. Аналитик должен убедиться, что полученные данные об инциденте соответствуют условиям корреляционных правил, настроенных для обнаружения определенного подозрительного поведения. Если данные инцидента не соответствуют логике правила или политики, инцидент может быть отмечен как ложноположительный.
Основная часть фазы анализа — расследование, которое состоит из сбора журналов, сбора дополнительной информации об активах и артефактах и определения области действия инцидента. Во время исследования аналитик должен собрать все данные об инциденте, чтобы определить точку входа и «нулевого пациента», — узнать, как атакующие получили несанкционированный доступ и какой хост или учетная запись были скомпрометированы первыми. Эта информация важна, так как помогает выбрать подходящие меры по сдерживанию и предотвратить подобные атаки в будущем. На этом этапе вы получаете информацию о некоторых объектах (активах и артефактах), связанных с инцидентом, — имена хостов, IP-адреса, хеши файлов, URL-адреса и т. д. — и можете использовать ее для расширения области анализа.
Расширив область анализа в соответствии с областью действия инцидента, аналитик может получить дополнительную информацию об активах и артефактах из источников данных об угрозах (Threat Intelligence) или локальных систем с инвентаризационными данными, например Active Directory, IDM (системы управления учетными данными) или CMDB (базы данных управления конфигурациями). Опираясь на информацию о затронутых активах, команда реагирования может определить возможные последствия и риск угрозы, а также выбрать подходящие меры дальнейшего реагирования. Они зависят от того, сколько хостов, пользователей, систем, бизнес-процессов или клиентов пострадали от атаки. При этом возможны разные сценарии эскалации. Если уровень риска средний, для сдерживания инцидента и нейтрализации его последствий следует уведомить только руководителя центра мониторинга и реагирования и администраторов затронутых систем. Если же риск критичный, может понадобиться оповещение об инциденте кризисной группы, топ менеджмента, а в некоторых случаях и регулирующего органа.
На последнем этапе анализа команда реагирования уведомляет об инциденте всех заинтересованных лиц. Это необходимо сделать своевременно, чтобы владелец системы обеспечил эффективное сдерживание угрозы и меры по восстановлению.
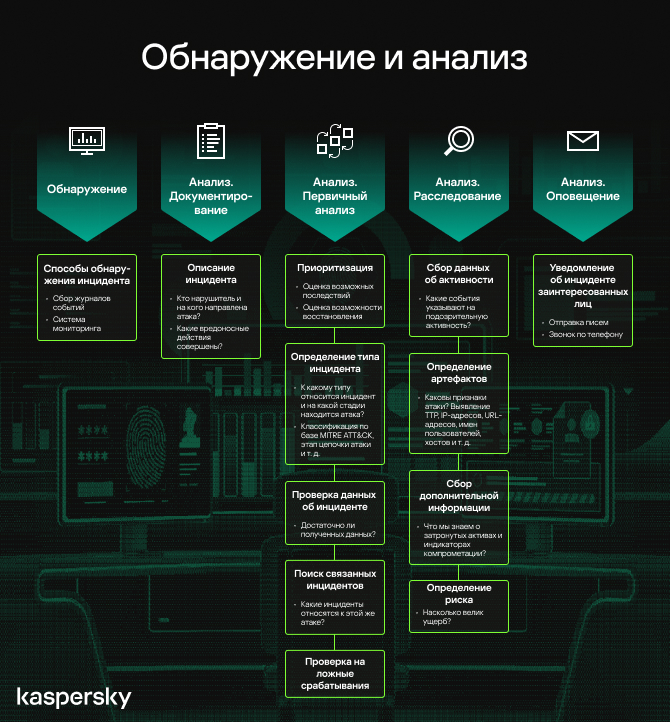
Действия аналитика в фазе обнаружения и анализа
3. Сдерживание — одна из наиболее важных фаз для минимизации последствий инцидента
Следующая значительная часть жизненного цикла инцидента состоит из фаз сдерживания, устранения и восстановления. Основная цель сдерживания — взять ситуацию под контроль после того, как произошел инцидент. Команда должна понимать, какие меры сдерживания использовать в зависимости от степени серьезности инцидента и потенциального ущерба.
Определив порядок действий на предварительном этапе, мы получили список различных типов объектов и действий, которые можно выполнить с имеющимся набором инструментов. Из списка действий нам нужно лишь выбрать подходящие меры, соответствующие последствиям инцидента. Этот этап во многом определяет итоговый ущерб: чем согласованнее и точнее определены в сценарии действия для этой фазы, тем быстрее мы сможем блокировать вредоносную активность и свести последствия к минимуму. В процессе сдерживания аналитик может, например, удалять вредоносные файлы или блокировать их запуск, изолировать хосты в сети, отключать учетные записи или запускать сканирование дисков защитными решениями.
Фазы устранения и восстановления похожи и состоят из процедур, направленных на возврат системы к штатному состоянию. В фазе устранения из инфраструктуры удаляются все признаки проникновения, такие как созданные злоумышленниками вредоносные файлы, запланированные задачи и службы. Восстановление означает возвращение системы к обычному режиму работы. Как и устранение, восстановление не является обязательной фазой, так как не каждый инцидент оказывает влияние на инфраструктуру. В этой фазе команде реагирования следует провести проверку работоспособности системы и при необходимости откатить изменения, произведенные как в процессе самой атаки, так и в рамках реагирования на атаку (что не всегда нужно делать, если например изменения производились для улучшения состояния защищенности и изменения не влияют на бизнес функцию).

Меры по сдерживанию инцидента и восстановлению системы
4. Работа над ошибками: пост-инцидентный анализ
Последняя фаза сценария — пост-инцидентный анализ, или работа над ошибками. Основная цель в этой фазе — понять, как улучшить процесс реагирования. Чтобы упростить задачу, можно сформировать список вопросов и попросить команду реагирования ответить на них, например:
- Насколько хорошо команда реагирования справилась с инцидентом?
- Какую информацию требовалось бы получить быстрее?
- Могла ли команда продуктивнее делиться информацией с другими организациями или отделами?
- Что команде стоит сделать иначе в случае повторного инцидента?
- Какие дополнительные инструменты или ресурсы требуются, чтобы помочь предотвратить подобные инциденты или смягчить их последствия?
- Совершила ли команда какие-либо ошибочные действия, которые повлекли за собой ущерб или задержали восстановление системы?
Ответив на вопросы, команда реагирования может обновить свою базу знаний, усовершенствовать механизм обнаружения и реагирования, скорректировать план реагирования на инциденты или даже разработать новый.
Заключение. Порядок разработки эффективного сценария реагирования
Чтобы разработать сценарий реагирования на инциденты кибербезопасности, мы должны определить процесс управления инцидентами — в частности, его фазы. Затем необходимо углубиться в детали и выбрать инструменты или системы, используемые для обнаружения инцидента, расследования, сдерживания угрозы, устранения последствий и восстановления. Зная набор инструментов, мы можем определить возможные действия:
- сбор журналов;
- дополнение информации о пострадавших активах данными из систем инвентаризации, телеметрией или данными о репутации из внешних источников (Threat Intelligence);
- сдерживание инцидента с помощью изоляции хостов, предотвращения запуска вредоносного ПО, блокирования ссылок, прекращение активных сессий, отключение учетных записей и т.п.;
- удаление последствий вторжения путем удаления файлов, подозрительных служб и запланированных задач, внесения изменений в настройки, правки реестра и т.п.;
- откат изменений и восстановление рабочего состояния системы;
- фиксация новых знаний, например написание новой статьи в локальной базе знаний или исправление механизма реагирования.
В процессе разработки сценария необходимо также определить сферы ответственности в команде реагирования, чтобы каждый участник знал свою роль и понимал, как от него зависит общий результат. Завершив подготовку, можно начать разрабатывать процедуры, из которых будет состоять сценарий. Как правило, каждая процедура или блок сценария выглядит следующим образом: «<Субъект> выполняет <действие> над <объектом>, используя <инструмент>». Все субъекты, действия, объекты и инструменты определены, и теперь их довольно легко можно комбинировать, составляя процедуры и сценарий в целом. Разумеется, при этом следует помнить о плане реагирования со всеми его фазами и придерживаться его.
Содержание
- Определение порядка действий — необходимый предварительный этап для разработки сценария
- 1. Подготовка к обработке инцидентов
- 2. Создание подходящих условий для расследования
- 3. Сдерживание — одна из наиболее важных фаз для минимизации последствий инцидента
- 4. Работа над ошибками: пост-инцидентный анализ
- Заключение. Порядок разработки эффективного сценария реагирования
В той же категории












Разработка сценариев реагирования на инциденты