

Авторы
DLL Hijacking — распространенная техника, при которой злоумышленники подменяют библиотеку, вызываемую легитимным процессом, на вредоносную. Ею пользуются как авторы вредоносного ПО «массового поражения», например стилеров или банковских троянцев, так и APT- и киберпреступные группы, стоящие за целевыми атаками. При этом в последние годы число атак с применением DLL Hijacking значительно выросло.
Динамика числа атак с использованием техники DLL Hijacking. За 100% приняты данные за 2023 год (скачать)
Мы видели эту технику и различные ее вариации, такие как DLL Sideloading, в целевых атаках на организации в России, Африке, Южной Корее и других странах и регионах мира. С ее помощью распространяется Lumma, один из наиболее активных стилеров на 2025 год. Злоумышленники, пытающиеся нажиться на популярных приложениях наподобие DeepSeek, также прибегают к DLL Hijacking.
Обнаружить атаку с подменой DLL не так просто: библиотека выполняется в адресном пространстве легитимного процесса, который ей доверяет. Поэтому для защитного решения ее активность может выглядеть как активность доверенного процесса. При этом слишком пристальное внимание к поведению доверенных процессов может негативно повлиять на общую производительность системы, и приходится искать тонкий баланс между достаточной безопасностью и достаточным удобством.
Детектирование DLL Hijacking при помощи модели машинного обучения
Там, где простые алгоритмы детектирования не справляются, на помощь может прийти искусственный интеллект. «Лаборатория Касперского» уже 20 лет применяет машинное обучение для выявления вредоносной активности на разных стадиях. Центр экспертизы AI исследует возможности различных моделей в сфере детектирования угроз, обучает и внедряет их. Коллеги из центра исследования угроз обратились к нам с вопросом, можно ли детектировать DLL Hijacking с помощью машинного обучения, — а главное, поможет ли оно повысить точность обнаружения.
Подготовка
Чтобы понять, можем ли мы обучить модель отличать загрузку вредоносной библиотеки от загрузки легитимной, нужно в первую очередь определить набор признаков, которые с высокой вероятностью указывают на DLL Hijacking. Мы выделили следующие основные признаки:
- Библиотека лежит не там. Многие стандартные библиотеки находятся в стандартных директориях, тогда как подменная DLL часто расположена в необычном месте, например в одной папке с исполняемым файлом, который ее вызывает.
- Исполняемый файл лежит не там. Злоумышленники часто сохраняют исполняемые файлы по нестандартным путям, например во временной директории или в пользовательской папке, а не в %Program files%.
- Исполняемый файл переименовали. Для ухода от обнаружения злоумышленники часто сохраняют легитимные приложения под произвольными именами.
- Размеры библиотеки изменились, и она перестала быть подписанной.
- Изменилась структура библиотеки.
Обучающая выборка и разметка
В качестве обучающей выборки мы взяли данные о загрузках динамических библиотек, полученные как от наших внутренних систем автоматической обработки, через которые проходят миллионы файлов ежедневно, так и из телеметрии, в том числе добровольно предоставленной пользователями решений «Лаборатории Касперского» в анонимизированном виде через Kaspersky Security Network.

Разметка обучающей выборки проходила в три итерации. Изначально у нас не было возможности автоматически подтянуть разметку событий от аналитиков с информацией о том, относится ли событие к атаке DLL Hijacking. За основу мы взяли данные из наших баз, содержащие репутацию файлов. Всю дальнейшую разметку мы делали на своей стороне. Как DLL Hijacking мы обозначили события вызова библиотеки, в которых процесс был однозначно легитимным, а DLL — однозначно вредоносной. Однако такой разметки оказалось недостаточно, поскольку существуют процессы, такие как svchost, основная задача которых — загружать различные библиотеки. Как результат, обученная на этих данных модель показала высокую долю ложноположительных срабатываний и для применения на практике не годилась.
В следующей итерации мы дополнительно отфильтровали вредоносные библиотеки по семействам, оставив в категории DLL Hijacking только те из них, которые могут демонстрировать такое поведение. Обученная на этих данных модель показала значительно большую точность и фактически подтвердила гипотезу, что детектировать атаки такого типа с помощью машинного обучения возможно.
На этом этапе обучающая выборка состояла уже из нескольких десятков миллионов объектов, среди которых около 20 миллионов были чистыми файлами и около 50 тысяч — однозначно вредоносными.
| Статус | Всего | Уникальных файлов |
| Неизвестен | ~ 18 млн | ~ 6 млн |
| Вредоносный | ~ 50 тыс. | ~ 1000 |
| Чистый | ~ 20 млн | ~ 250 тыс. |
Последующие модели мы обучали на результатах работы их предшественников, проверенных и доразмеченных аналитиками. Это позволило нам значительно повысить эффективность обучения.
Загрузка DLL-библиотек: как выглядит норма
Итак, у нас есть размеченная выборка с большим количеством событий загрузки библиотек различными процессами. Как мы можем описать «чистую» библиотеку? Если использовать связку «имя процесса + имя библиотеки», то мы не учтем переименованные процессы. При этом переименовать процесс может не только злоумышленник, но и легитимный пользователь. Если вместо имени процесса использовать его хэш, мы решим проблему переименований, но тогда каждая версия одной библиотеки будет считаться за отдельную библиотеку. Поэтому мы остановились на связке «имя библиотеки + подпись процесса». Хотя в таком варианте мы будем считать одной библиотекой все одноименные библиотеки одного вендора, в целом эта связка даст более-менее реалистичную картину.
В свою очередь, чтобы описать безопасные события загрузки библиотеки, мы использовали набор счетчиков, включающих в себя информацию о процессах, такую как частота встречаемости конкретного имени процесса для файла с таким хэшем, частота встречаемости конкретного пути к файлу с таким хэшем и т. д.; информацию о библиотеках, такую как частота встречаемости конкретного пути для этой библиотеки, доля легитимных запусков и т. д.; свойства событий, например, находится ли библиотека в той же директории, что и файл, который ее вызывает.
В результате мы получили систему со множеством агрегатов (наборов счетчиков и ключей), с помощью которых можно описать входное событие. Агрегаты могут содержать один (например, хэш-сумма DLL) или несколько (например, хэш-сумма процесса + подпись процесса) ключей. На основе этих агрегатов мы можем получить набор признаков, описывающих событие загрузки библиотеки. На схеме ниже приводятся примеры получения таких признаков:
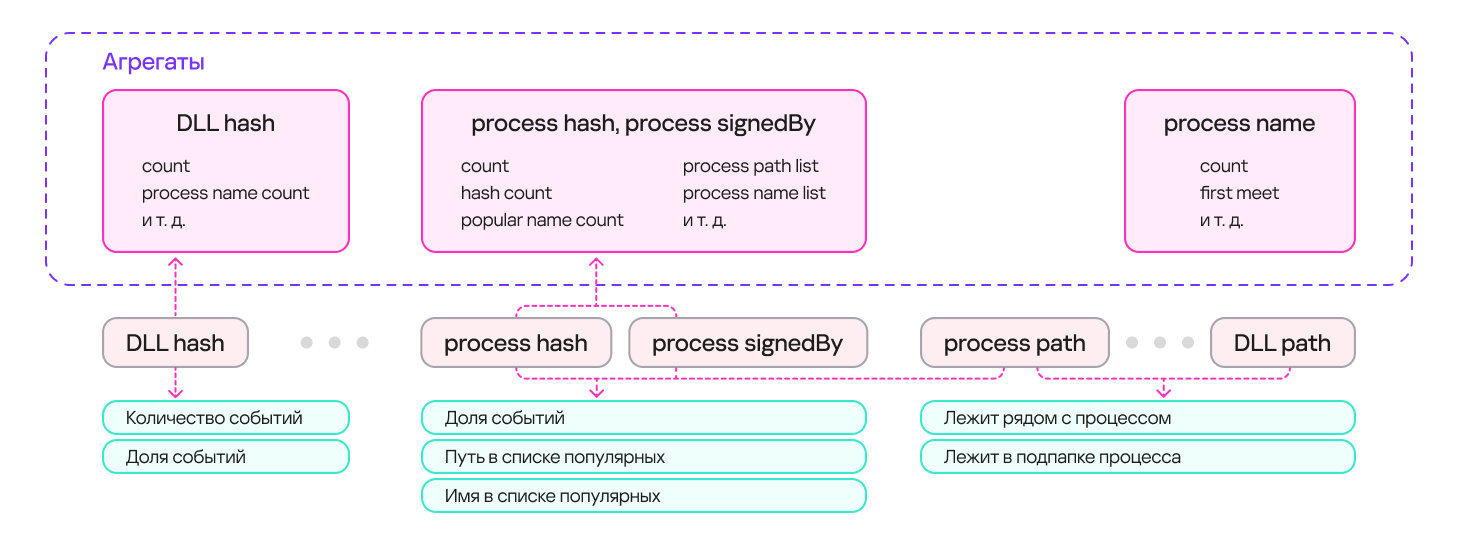
Получение признаков из агрегатов
Загрузка DLL-библиотек: как описать Hijacking
Некоторые сочетания признаков (зависимости) с высокой долей вероятности указывают на DLL Hijacking. Это могут быть простые зависимости. Так, для некоторых процессов чистая библиотека, которую они вызывают, всегда лежит в отдельной папке, тогда как вредоносная чаще всего помещается в папку процесса.
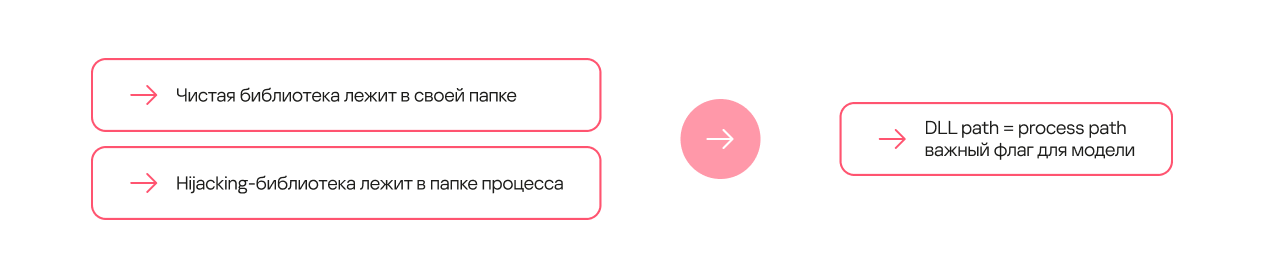
Другие зависимости могут быть сложнее и требовать выполнения нескольких условий. Например, само по себе переименование процесса не указывает на DLL Hijacking, но если при этом новое имя встречается в потоке данных впервые, а библиотека находится по нестандартному пути, то она с высокой долей вероятности вредоносная.

Эволюция моделей
В рамках проекта мы обучили несколько поколений моделей. Основная задача первого поколения была показать, что машинное обучение в принципе можно применять для детектирования DLL Hijacking. При обучении этой модели мы использовали максимально широкую трактовку термина.
Схема работы модели была максимально простая:
- Берем поток данных и получаем из него частотное описание для избранных наборов ключей.
- Берем тот же самый поток данных за другой период времени и получаем набор признаков.
- Применяем разметку типа 1, где как DLL Hijacking помечены события загрузки легитимным процессом вредоносной библиотеки из заданного набора семейств.
- На полученных данных обучаем модель.
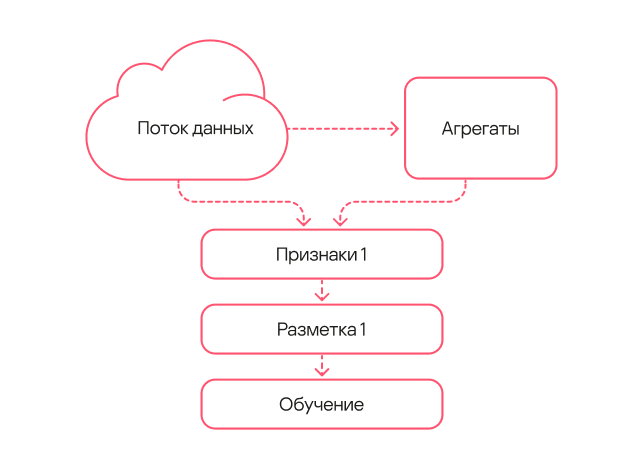
Схема работы модели первого поколения
Модель второго поколения обучалась на данных, обработанных моделью первого поколения и верифицированных аналитиками (разметка типа 2). Как следствие, разметка была более точной, чем при обучении первой модели. Кроме того, в описание загрузок библиотек мы добавили дополнительные признаки, описывающие структуру библиотеки, и несколько усложнили схему.

Схема работы модели второго поколения
По результатам работы этой модели второго поколения мы смогли выделить несколько распространенных типов ложноположительных срабатываний. Например, в разметку попали потенциально нежелательные приложения, которые в определенном контексте могут демонстрировать поведение, похожее на DLL Hijacking, однако в большинстве случаев к этому типу атаки не относятся и не являются вредоносными.
Работу над ошибками мы сделали в модели третьего поколения. Во-первых, при содействии аналитиков пометили в обучающей выборке приложения типа HackTool, чтобы модель не детектировала их. Во-вторых, в новой версии использовали расширенную разметку, содержащую полезные детекты первого и второго поколения. Кроме того, расширили признаковое описание за счет one-hot encoding — техники преобразования категориальных признаков в бинарный формат — для определенных полей. Также, поскольку с течением времени объем обрабатываемых моделью событий возрастал, в этой версии мы добавили нормировку всех признаков на величину потока данных.
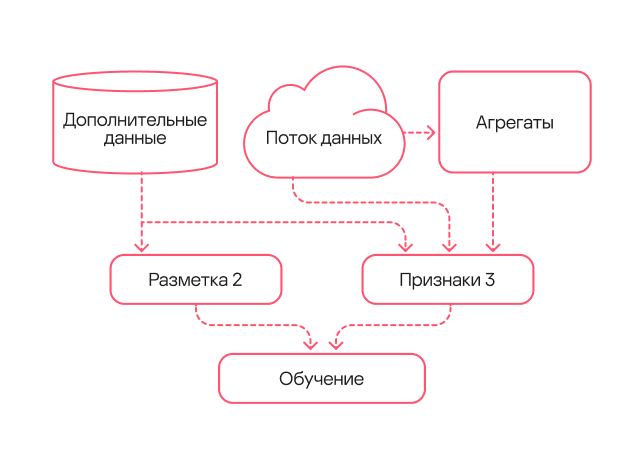
Схема работы модели третьего поколения
Сравнение моделей
Чтобы оценить развитие наших моделей, мы применили их к тестовым данным, с которыми ни одна из них до этого не работала. На графике ниже можно видеть соотношение истинно положительных и ложноположительных вердиктов для каждой модели.

Динамика числа истинно положительных и ложноположительных срабатываний моделей первого, второго и третьего поколений
По мере развития моделей доля истинно положительных срабатываний росла: если первое поколение дает относительно неплохой результат (0,6 и выше) только при высокой доле (10–3 или более) ложноположительных, то второе — уже при 10–5, а третье поколение при такой же доле ложноположительных вердиктов дает 0,8 истинно положительных, что уже может считаться хорошим результатом.
Если оценивать модели на потоке при зафиксированном скоре, то можно отметить, что абсолютное число новых событий, помеченных как DLL Hijacking, росло от поколения к поколению. При этом, если оценивать модели по доле неверных вердиктов, то также можно проследить прогресс: первая модель ошибается довольно часто, тогда как вторая и третья — значительно меньше.
Доля ошибок в результатах работы моделей, июль 2024 г. — август 2025 г. (скачать)
Практическое применение моделей
Все три поколения моделей используются в наших внутренних системах для поиска вероятных случаев DLL Hijacking в потоках данных с телеметрии. Ежедневно к нам поступает 6,5 миллионов событий безопасности, связанных с 800 тысячами уникальных файлов. На этой выборке раз в заданный период строятся агрегаты, которые обогащаются и загружаются в модели. Выходные данные мы ранжируем по модели и по вероятности DLL Hijacking, которую она присвоила событию, и отдаем аналитикам. Так, если третья модель с высокой долей уверенности оценивает событие как DLL Hijacking, то его стоит проверить в первую очередь, тогда как менее однозначный вердикт первой модели — в последнюю.
Параллельно модели проверяются на тестовом потоке данных, с которыми они ранее не работали. Это делается для оценки динамики эффективности: с течением времени модель может начать детектировать хуже. На графике ниже видно, что доля верных детектов незначительно варьируется с течением времени, однако в среднем модели выявляют 70–80% случаев DLL Hijacking.
Динамика эффективности моделей (данные по работе всех трех поколений), октябрь 2024 г. — сентябрь 2025 г. (скачать)
Кроме того, недавно мы внедрили модель для детектирования DLL Hijacking в SIEM-платформу Kaspersky Unified Monitoring and Analysis Platform (KUMA), предварительно протестировав ее в сервисе Kaspersky MDR. На этапе пилотирования модель помогла обнаружить и предотвратить ряд инцидентов, связанных с DLL Hijacking, в системах наших клиентов.О том, как модель машинного обучения для обнаружения целевых атак с применением техники DLL Hijacking работает в нашем решении KUMA и какие инциденты она выявила, мы написали отдельную статью.
Заключение
По итогам обучения и применения трех поколений моделей можно сказать, что эксперимент по детектированию DLL Hijacking при помощи машинного обучения оказался успешным. Мы смогли разработать модель, отличающую события, похожие на DLL Hijacking, от прочих событий, и довели ее до состояния, пригодного к применению на практике не только в наших внутренних системах, но и в коммерческих продуктах. На данный момент модели работают в облаке, проверяют сотни тысяч уникальных файлов и детектируют тысячи файлов, использующихся в атаках типа DLL Hijacking, в месяц, причем регулярно выявляют ранее неизвестные вариации таких атак. Результаты работы моделей поступают на разбор аналитикам, которые их верифицируют и создают новые детекты на их основе.












Как мы научили ML-модель детектировать DLL Hijacking